












Virtual Memory For 640K DOS
This article originally appeared in the July 1990 issue of The C Users Journal. It is reprinted here with the kind permission of the publisher.
[Ed. Note: Zortech's newest release v2.1 includes a virtual code manager (VCM) which allows even 8088-based machines to ignore the 640K barrier. Here the implementor, Walter Bright, describes how the technology works.]
As time goes by, programs tend to steadily increase in size and complexity. There are many reasons for this. Customers want more features, unanticipated problems require more code to solve, programming in a high level language results in larger programs than assembler. As code size grows, so does the amount of data memory needed. Pretty soon you start bumping up against the notorious "640k barrier" that MS-DOS programmers have all learned to love.
The solutions available are:
- Recode to reduce code size,
- or "How I learned to stop worrying and love assembler language". This alternative may produce modest decreases in program size, but is very costly in terms of schedule slides.
- Stop adding features.
- Yeah, right!
- Port to OS/2
- - if you and all your customers can afford the hardware and software costs.
- Use a DOS Extender.
- This approach works well, and is cheaper than the OS/2 route, but requires a 286 or better, with lots of extended memory.
- Use overlays.
- This traditional technique involves swapping code off disk instead of keeping it resident in memory all the time. Overlays will be discussed shortly.
- Use VCM (Virtual Code Manager).
- VCM is a technique whereby virtual memory can be simulated, even on lowly 8088-based machines. VCM, what it is and how it works, is the primary focus of this article.
Traditional Overlay Methods
Overlay schemes work by dividing up a program's code into a root segment and various overlay segments. The root segment is always resident in memory. The overlay segments are placed into a reserved section of memory, called the overlay region. An overlay is loaded only when the program calls a function in that overlay. When an overlay is loaded, it replaces any existing overlay in the overlay region. The size of the overlay region is the size of the largest overlay segment. The layout in memory of a typical program with three overlays is shown in Figure 1. Since Overlay C is the largest, it determines the size of the overlay region.
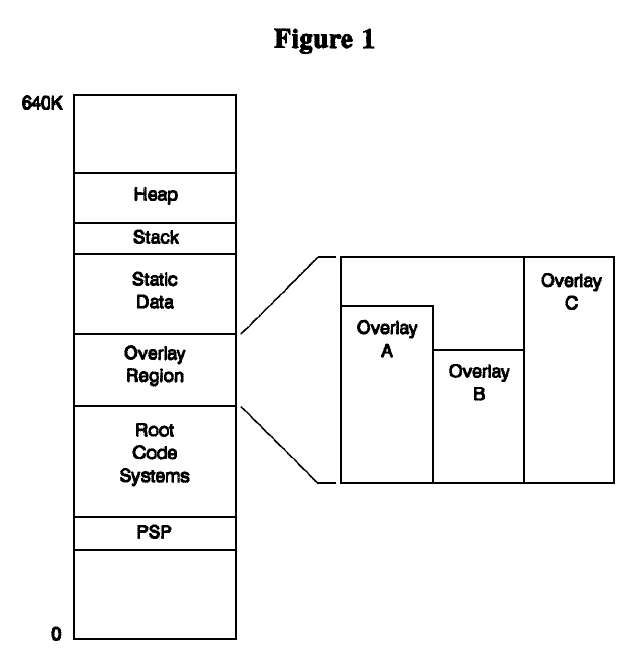
The linker sets up overlays. A command to the linker to set up the overlays in Figure 1 is something like:
LINK root1+root2+(ovla)+(ovlb)+(ovlc),prog;
The linker replaces all calls to functions in the overlays with calls to the overlay manager, which loads the appropriate overlay into the overlay region before jumping to the called function.
The overlay process begins to break down when more than a few overlays are needed. It seems that every function called is in a different overlay, and that overlays therefore always need to be loaded in from disk. This is a condition known as "thrashing", and results in terrible performance. For a simplistic example, imagine the following code:
for (i = 0; i < 10; i++) // in overlay A
{ funcb(); // in overlay B
funcc(); // in overlay C
}
Running this code will cause the disk drive light to come on, and stay on. One time through the loop will cause overlay A to be loaded 2 times, and overlay B and C to be overloaded once each. That seems rather silly when lots of memory might be available.
More sophisticated overlay linkers try to deal with this problem by allowing overlay 'hierarchies', that is, the overlay structure looks like an inverted tree (see Figure 2). Here, overlay B can be in memory at the same time as overlay B1, and B at the same time as B2, and C at the same time as C2. But no other simultaneous combinations are possible. Some implementations don't even allow calls between leaves, that is, B1 cannot call C1. Most programs simply don't decompose into such simple trees.
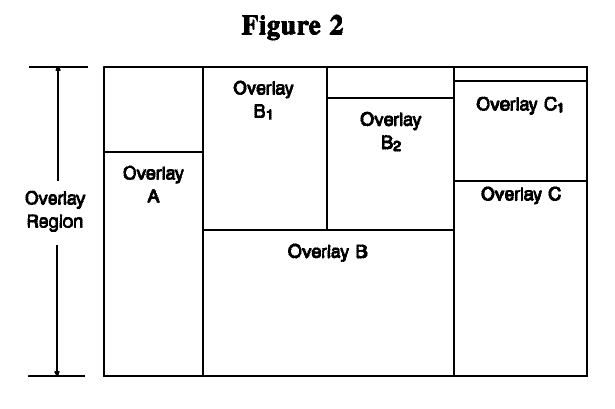
It is important to remember that the overlays are statically located by the linker. They are loaded on demand into a fixed location in the program, regardless of what other memory is available. The program is organized into an overlay structure at compile/link time. There is no flexibility based on user usage patterns or memory available at run time.
What's needed is a scheme with the following capabilities:
- Overlay segments are loaded into whatever free memory might be available.
- As the demand for data memory increases (via calls to malloc), the overlay manager discards overlay segments from memory, using a least-recently-used (LRU) algorithm.
- Decent performance on both 640K XT and AT machines.
- Requires no special attention from programmers.
- Works with pointers to functions (necessary to work with virtual functions in C++).
- Works with debuggers.
VCM is a solution that meets these requirements. Instead of a fixed overlay region, when the VCM manager needs memory to load an overlay segment (or vseg, virtual code segment), it calls malloc() to get the memory. The vseg is then loaded from disk into this region. When malloc() runs out of free memory, it calls the VCM manager, which discards vsegs from memory until the request to malloc() can be satisfied. Thus, the layout of code in memory is dynamically adjusted to reflect the memory available and the usage pattern. Only under worst case conditions does the performance degrade to that of the traditional static overlay schemes (a buffer is set aside so that there is always room to load at least one vseg). The layout in memory of a VCM program at one particular instant is shown in Figure 3.
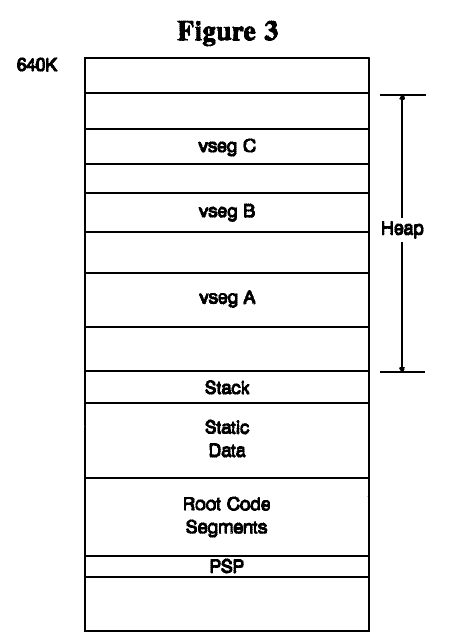
How does VCM work? The 8088 does not support position-independent code. A far function call consists of 5 bytes:
0x9A, offset-low, offset-high, seg-low, seg-high
With VCM, functions can't be invoked with far calls because we don't know at link time where a vseg will wind up. The possible cases are:
- Call from root to another function in the root. A far call will work; this is what the linker normally does anyway!
- Call from root to a function in a vseg;
the far function calls are replaced with these 5 bytes:
INT 3Fh ;call VCM manager db vcsnum ;number of virtual code segment dw voffset ;offset within that code segment
Note that this implies a maximum of 255 virtual code segments. If the vseg is resident, VCM jumps to the start of the vseg offset by the voffset word. If the vseg is not resident, VCM allocates space for it via malloc, loads it from disk, and jumps to it. - Call from a vseg to another function in the same vseg.
This is converted to a near function call:
push CS ;the function will do a far return call near ptr function nop ;to fill it out to 5 bytes
Fortunately, near function calls are position independent. Note that a vseg has only one code segment, separate from any other segment, so near function calls never cross vseg boundaries. - Call from a vseg to another function in a different vseg: Do the same thing as with case 2.
- Call from a vseg to a function in the root: Do the same thing as with case 1. However, since at link time can't know at what segment value the root will be loaded, when VCM loads a vseg, it must be relocated, much like .EXE files are relocated when loaded.
Other Problems
How about pointers to functions? A far function pointer is a 32-bit value: the segment and offset. How can this address be fixed, when the code can move around at runtime? The trick here is to replace the address of the function with the address of a thunk. The thunk is a 5-byte entity that the linker adds to the program. The thunk is always resident, and stays at a fixed address. The thunk consists of:
INT 3Fh ;call VCM manager db vcsnum ;number of virtual code segment dw voffset ;offset within that code segment
These pointers to functions are converted to VCM calls using the same mechanism which converts direct function calls to VCM calls. The function pointer now points to this reload thunk. When the function pointer is called, control is actually transferred to the reload thunk, which calls the VCM manager to load the vseg, which then jumps to the actual function.
So far, it's all fairly straightforward. Now comes the tricky part. Suppose the code in vseg A calls a function in vseg B. Now B calls malloc() a few times, and causes vseg A to get discarded from memory. The return address into vseg A is still on the stack, but now points into data! Returning from that function will cause a crash. Thus, when vseg A is discarded, the stack must be walked to find any return addresses into vseg A. Thse return addresses are then replaced with the addresses of reload thunks for vseg A. In order to walk the stack, and distinguish far return addresses from any other stuff that might be on the stack, some conventions must be carefully observed. A typical stack frame generated for a function looks like:
func proc far
push BP
mov BP,SP
sub SP,10 ;make space for local variables
....
add SP,10
pop BP ;get caller's BP
ret
func endp
So the return address is always a fixed offset from BP, and BP can be used to find the stack frames as the stack is walked back wards. Since we must skip any near function calls (recall that the return addresses are position independent and no near calls could cross a vseg boundary), we must also find a way to distinguish a near call on the stack from a far one.
The trick is to notice that the stack is always word aligned, that is, the least significant bit is always 0. This bit can be used as a flag to indicate a far stack frame. The stack frame code is modified to:
func proc far
inc BP ;indicate far return address on stack
push BP
mov BP,SP
sub SP,10 ;make space for local variables
....
add SP,10
pop BP ;get caller's BP
dec BP ;counteract previous inc
ret
func endp
near functions would not have the inc BP / dec BP pair. The stack walker now looks at bit 0 of BP for each frame to see if the return address is far or near.
The same syntax to the linker is used to specify vseg modules, as was used for the older overlay schemes, i.e.:
BLINK root1+root2+(vcsa+vcsb)+(vcsc)+(vcsd),prog,,(mlib.lib);
Three vsegs are created (vcsa and vcsb are combined into one vseg). Enclosing the library mlib in parentheses tells the linker to place each module pulled in from the library in its own vseg. Interestingly, even main() can be put into a vseg! The only thing that cannot be put into a vseg is the C runtime library, because that contains the VCM initialization code, which had better not get discarded.
That's how it works. There's one more problem, though. The compiler must be modified to produce the inc BP / dec BP pairs. The trouble is, if one module is linked to another, and one has the pairs and the other doesn't, mysterious and erratic program crashes may occur. The solution is to create a new memory model in addition to the standard T,S,C,M,L models, called the V model. All modules are compiled with the V model, and the VCM linker verifies that all were compiled with the V model.
For assembler programmers, the linker cannot verify that the stack frame conventions are followed, so the responsibility rests with the programmer. The stack frame is required for any function that calls malloc or calls another function which might call malloc or exist in another vseg. When in doubt, put the stack frame on all functions which call other functions.
All the information and vseg code needed by VCM is stored into the .EXE program file. It is disguised as a Microsoft-style overlay, so that various programs that fiddle around with .EXE files will not disturb it. Since the vsegs are loaded from the .EXE file, the runtime performance of VCM can be improved by running the program from a RAM disk.
Typical debuggers cannot deal with code that moves around at runtime. Zortech's debugger was modified to work with VCM so debugging VCM programs is as easy as debugging regular programs.
VCM does not overlay data. VCM helps make room for data by discarding code that is not in use, but it cannot swap data to disk.
In conclusion, VCM is the ideal solution to a certain class of programming problems. It is well suited to programs that have large amounts of code, have widely varying amounts of data, and that must run on 8088 machines. A program fitting this criteria is a word processor. Word processing programs typically are loaded with features, each requiring significant code to implement. Different customers would use different features. The code to implement these features takes away from the memory needed for the data. With VCM, only those features which are actually being used have the code for them in memory. If there is not much data in the document being edited, the needed code is all resident in memory and the program runs at maximum speed. As the data grows in size, less frequently used code is discarded. Performance gets slower, and eventually reaches the worst case, which is that of the traditional static overlay scheme.
Since VCM's worst case performance is that of static overlays, and typically will be far superior, VCM completely obsoletes those old overlay schemes.