







digitalmars.D - std.d.lexer : voting thread
- Dicebot (18/43) Oct 02 2013 After brief discussion with Brian and gathering data from the
- =?UTF-8?B?IkFuZHLDqSI=?= (1/1) Oct 02 2013 Yes!
- Jacob Carlborg (6/9) Oct 02 2013 Yes.
- Dejan Lekic (4/13) Oct 04 2013 Yes, I agree with Jacob.
- =?UTF-8?B?IsOYaXZpbmQi?= (2/45) Oct 02 2013 Yes! :)
- Justin Whear (2/2) Oct 02 2013 Yes.
- Daniel Kozak (2/45) Oct 02 2013 Yes :)
- Mike Parker (1/1) Oct 03 2013 Yes!
- Chris (2/45) Oct 03 2013 Yes.
- Namespace (1/1) Oct 03 2013 Yes
- Dicebot (3/3) Oct 03 2013 Yes.
- Tove (12/15) Oct 03 2013 I'd love to say yes, since I've been dreaming of the day when we
- nazriel (6/12) Oct 03 2013 Yes.
- Brian Schott (7/11) Oct 03 2013 The most recent set of timings that I have can be found here:
- Andrei Alexandrescu (5/16) Oct 03 2013 I see we're considerably behind dmd. If improving performance would come...
- Brad Anderson (4/28) Oct 03 2013 Considerably? They look very similar to me. dmd is just
- Andrei Alexandrescu (3/28) Oct 03 2013 To me 10% is considerable.
- Dicebot (4/4) Oct 03 2013 Please express your opinion in a clear "Yes", "No" or "Yes, if"
- Andrei Alexandrescu (3/7) Oct 03 2013 That's why I renamed the thread! I didn't vote.
- Dicebot (6/16) Oct 03 2013 I mean I will be forced to ignore your opinion in current form
- Dejan Lekic (12/36) Oct 04 2013 Quite frankly, I (or better say many of us) need a COMPLETE D
- Brian Schott (12/16) Oct 04 2013 The old benchmarks measured total program run time. I ran a new
- Jacob Carlborg (4/9) Oct 04 2013 If these results are correct, me like :)
- Piotr Szturmaj (4/19) Oct 04 2013 Interestingly, DMD is only faster when lexing std.datetime. This is
- Dmitry Olshansky (9/24) Oct 11 2013 I'm suspicious of:
- Jonathan M Davis (20/52) Oct 11 2013 d
- Dmitry Olshansky (4/44) Oct 11 2013 --
- Jonathan M Davis (20/65) Oct 11 2013 uld
- Dmitry Olshansky (6/56) Oct 11 2013 I was looking at dmd.diff actually in linked repo.
- David Nadlinger (11/13) Oct 03 2013 How exactly were these figures obtained?
- Dicebot (2/4) Oct 03 2013 Please keep "btw"s in separate thread :)
- deadalnix (10/15) Oct 03 2013 I sadly have to vote no in the current state.
- Martin Nowak (17/20) Oct 03 2013 I also have to vote with no for now.
- Martin Nowak (2/3) Oct 03 2013 And working in CTFE can't be easily given up either.
- David Nadlinger (9/10) Oct 03 2013 I would be in favor of adding such community-reviewed but
- Robert (7/20) Oct 04 2013 I created https://github.com/phobos-x/phobosx for this, it is also in
- Dejan Lekic (3/6) Oct 04 2013 Martin, that is truly a matter of taste. I, for an instance, do
- Jakob Ovrum (4/7) Oct 04 2013 No.
- ilya-stromberg (42/45) Oct 04 2013 No.
- Craig Dillabaugh (5/16) Oct 04 2013 clip
- ilya-stromberg (3/25) Oct 04 2013 I said: "TRY to add". But yes, I feel that `std.d.lexer` don't
- Craig Dillabaugh (4/32) Oct 04 2013 I think it was a good idea ... it just sort of jumped out at me
- H. S. Teoh (8/17) Oct 04 2013 The rest of Phobos docs *should* be put to shame. Except maybe for a few
- Andrei Alexandrescu (4/26) Oct 04 2013 I would say matters that are passable for now and easy to improve later
- Andrei Alexandrescu (100/103) Oct 04 2013 Thanks all involved for the work, first of all Brian.
- deadalnix (9/44) Oct 04 2013 That is more or less how SDC's lexer works. You pass it 2AA : one
- Walter Bright (13/15) Oct 04 2013 Well, boys, I reckon this is it — benchmark combat toe to toe with the...
- Jacob Carlborg (11/15) Oct 05 2013 Is this something in the middle of a hand written lexer and a lexer
- Artur Skawina (32/33) Oct 05 2013 The assumption, that a hand-written lexer will be much faster than a gen...
- Jacob Carlborg (5/7) Oct 06 2013 I never said that the generated one would be slow. I only said that the
- Artur Skawina (42/49) Oct 07 2013 I know, but you said that having both is an option -- that would not
- Andrei Alexandrescu (11/27) Oct 05 2013 I agree with Artur that this is a fallacy.
- Jacob Carlborg (9/23) Oct 06 2013 I never said that the generated one would be slow. I only said that the
- ilya-stromberg (8/12) Oct 06 2013 Maybe we went to the voting too fast, and somebody had not enough
- Dicebot (19/24) Oct 06 2013 There were more than 1 week of time between last comment in
- ilya-stromberg (8/13) Oct 07 2013 Yes, but people are lazy. I don't talk about all of us, but most
- simendsjo (5/18) Oct 07 2013 This is the reason I've not cast any votes for standard modules -
- Jonathan M Davis (3/23) Oct 07 2013 So, it would be like your typical political vote then. ;)
- Andrei Alexandrescu (10/19) Oct 06 2013 I've always thought we must invest effort into generic lexers and
- ilya-stromberg (4/21) Oct 05 2013 I asked the same question about support any grammar, not only D
- Jacob Carlborg (7/16) Oct 06 2013 Would it be able to lex Scala and Ruby? Method names in Scala can
- Andrei Alexandrescu (4/18) Oct 06 2013 Yes, easily. Have the trie matcher stop upon whatever symbol it detects
- dennis luehring (7/10) Oct 06 2013 would it be also more efficent to generate a big string out of the token...
- Joseph Rushton Wakeling (6/121) Oct 06 2013 How quickly do you think this vision could be realized? If soon,
- Andrei Alexandrescu (14/17) Oct 06 2013 I'm working on related code, and got all the way there in one day
- Joseph Rushton Wakeling (4/14) Oct 06 2013 What I'm getting at is that I'd be prepared to give a vote "no to std, y...
- Dmitry Olshansky (25/42) Oct 11 2013 This is something I agree with.
- Andrei Alexandrescu (16/58) Oct 11 2013 That's a good idea. The only concerns I have are:
- David Nadlinger (17/19) Oct 06 2013 What is your vision for the future of etc.*, assuming that we are
- Joseph Rushton Wakeling (5/8) Oct 06 2013 I actually realized I had no idea about what etc was until the last coup...
- David Nadlinger (5/8) Oct 06 2013 This is exactly why I'm not too thrilled to make another attempt
- Andrei Alexandrescu (5/12) Oct 06 2013 We could improve things on our end by featuring etc documentation more
- Brad Roberts (9/21) Oct 06 2013 I'm largely staying out of this conversation, but there's one area that ...
- Dicebot (14/44) Oct 07 2013 This.
- Andrei Alexandrescu (4/9) Oct 06 2013 I think /etc/ should be a stepping stone to std, just like in C++ boost
- Jacob Carlborg (4/6) Oct 06 2013 Currently "etc" seems like where C bindings are placed.
- Jonathan M Davis (6/11) Oct 07 2013 That's what I thought that it was for. I don't remember etc ever really ...
- SomeDude (13/29) Oct 12 2013 The problem is, if these C bindings are removed, the immediate
- Jonathan M Davis (17/50) Oct 12 2013 Deimos is for C bindings, not Phobos. We don't want any more modules in ...
- Paulo Pinto (4/54) Oct 13 2013 +1 for removing std.net.curl.
- SomeDude (4/5) Oct 13 2013 OK, for libraries that are not well supported on all platforms,
- Jonathan M Davis (12/19) Oct 13 2013 Yeah, and because Windows supports basically nothing out of the box exce...
- Jordi Sayol (4/59) Oct 13 2013 +1 for removing std.net.curl too
- Dejan Lekic (4/18) Oct 07 2013 Please consider the stdx proposal instead. etc was always used
- Andrei Alexandrescu (35/49) Oct 07 2013 [snip]
- Jakob Ovrum (9/10) Oct 07 2013 I have to say, that `generateCases` function is rather
- Andrei Alexandrescu (5/13) Oct 07 2013 This is the first shot, and I'm more interested in the API with the
- Andrei Alexandrescu (15/29) Oct 07 2013 FWIW I just tried this, and it seems to work swell.
- Andrei Alexandrescu (5/36) Oct 07 2013 On the other hand, I find it difficult to figure how the needed
- Jakob Ovrum (7/8) Oct 08 2013 I was going to cook something up with `groupBy` (taken from the
- Andrei Alexandrescu (12/18) Oct 08 2013 Fair enough. (Again, it would be unfair to compare an existing design
- Martin Nowak (8/14) Oct 09 2013 It's good to get rid of the symbol names.
- Andrei Alexandrescu (4/18) Oct 10 2013 Excellent point! In fact one would need to use t!"<<".id instead of t!"<...
- Brian Schott (4/8) Oct 10 2013 I don't suppose this new lexer is on Github or something. I'd
- Andrei Alexandrescu (6/16) Oct 10 2013 Thanks for your gracious comeback. I was fearing a "My work is not
- Dmitry Olshansky (6/16) Oct 11 2013 Love this attitude! :)
- Dmitry Olshansky (4/19) Oct 11 2013 s/land/lend/
- Martin Nowak (4/5) Oct 10 2013 Either adding an alias this from TokenType to the enum or returning the
- Jonathan M Davis (18/24) Oct 07 2013 I think that it's worth noting that if this vote passes, it will be the ...
- Brian Schott (4/17) Oct 07 2013 I had noticed this. I'm not sure if a simple majority is good
- Dicebot (8/15) Oct 08 2013 Guess what was the main point of my concerns while following this
- Martin Nowak (4/9) Oct 09 2013 It usually takes me a few month until I get to try a new module at which...
- ilya-stromberg (11/14) Oct 08 2013 Why do you use "\0" as end-of-stream token:
- Andrei Alexandrescu (10/23) Oct 09 2013 I'm glad you asked. It's simply a decision by convention. I know no C++
- ilya-stromberg (4/36) Oct 09 2013 So, it's interesting to see a new improved API, because we need a
- Andrei Alexandrescu (33/58) Oct 09 2013 I made an improvement to the way tokens are handled. In the paste above,...
- Dmitry Olshansky (21/55) Oct 11 2013 No - ctRegex as it stands right now is too generic and conservative with...
- Walter Bright (20/21) Oct 08 2013 Some points:
- Brad Anderson (3/9) Oct 08 2013 Github tip: You can link to a specific line by clicking the line
- Andrei Alexandrescu (15/35) Oct 08 2013 Thanks, that's exactly what I had in mind. Also the trie searcher should...
- deadalnix (14/70) Oct 08 2013 Overall, I think this is going into the right direction. However,
- Andrei Alexandrescu (3/13) Oct 08 2013 I think a bit of code would make all that much clearer.
- deadalnix (19/41) Oct 08 2013 Sure.
- Brian Schott (4/5) Oct 08 2013 YOU CALL YOURSELVES A COMMUNITY THAT CARES?
- Andrei Alexandrescu (4/8) Oct 08 2013 I swear I had that in mind when I wrote "the greater good". Awesome
- Araq (1/3) Oct 11 2013 This is wrong.
- =?UTF-8?B?U8O2bmtlIEx1ZHdpZw==?= (11/11) Oct 06 2013 Yes
- Martin Nowak (5/7) Oct 09 2013 The current API requires to copy slices of the const(ubyte)[] input to
- =?UTF-8?B?U8O2bmtlIEx1ZHdpZw==?= (4/11) Oct 10 2013 But it could be extended later to accept immutable input as a special
- Jonathan M Davis (15/18) Oct 09 2013 I'm going to have to vote no.
- Volcz (4/33) Oct 10 2013 Vote: No.
- Dmitry Olshansky (16/19) Oct 11 2013 I'd have to answer as NO.
- Dicebot (2/2) Oct 13 2013 Voting is closed.



After brief discussion with Brian and gathering data from the
review thread, I have decided to start voting for `std.d.lexer`
inclusion into Phobos.
-----------------------------------------------------
All relevant information can be found here:
http://wiki.dlang.org/Review/std.d.lexer (it includes link to
post-review change set and some clarifications by Brian)
Review thread is here:
http://forum.dlang.org/post/jsnhlcbulwyjuqcqoepe forum.dlang.org
-----------------------------------------------------
Instructions for voters
The goal of the vote is to allow the Review Manager to decided
if the
community agrees on the inclusion of the submission.
Place further discussion of the library in the official
review thread.
If replying to an opinion stated during a vote, copy all
relevant
context and post in the official review thread.
If you would like to see the proposed module included into
Phobos
Vote Yes
If one condition must be met
Vote Yes explicitly stating it is under a condition and
what condition.
You may specify an improvement you'd like to see, but be
sure to state
it is not a condition/showstopper.
Otherwise
Vote No
A brief reason should be provided though details on what
needs
improvement should be placed in the official review
thread.
(c) wiki.dlang.org/Review/Process
-----------------------------------------------------
If you need to ask any last moment questions before making your
decision, please do it in last review thread (linked in beginning
of this post).
Voting will last until the next weekend (Oct 12 23:59 GMT +0)
Thanks for your attention.
Oct 02 2013

 =?UTF-8?B?IkFuZHLDqSI=?= <andre andre.to>
=?UTF-8?B?IkFuZHLDqSI=?= <andre andre.to> 
On 2013-10-02 16:41, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Yes. Not a condition but I would prefer the default exception being thrown not to be Exception but a subclass. -- /Jacob Carlborg
Oct 02 2013
On Wednesday, 2 October 2013 at 18:41:32 UTC, Jacob Carlborg wrote:On 2013-10-02 16:41, Dicebot wrote:Yes, I agree with Jacob. Btw, you have a "Yes, if" vote here. :)After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Yes. Not a condition but I would prefer the default exception being thrown not to be Exception but a subclass.
Oct 04 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos. ----------------------------------------------------- All relevant information can be found here: http://wiki.dlang.org/Review/std.d.lexer (it includes link to post-review change set and some clarifications by Brian) Review thread is here: http://forum.dlang.org/post/jsnhlcbulwyjuqcqoepe forum.dlang.org ----------------------------------------------------- Instructions for votersYes! :)The goal of the vote is to allow the Review Manager to decided if the community agrees on the inclusion of the submission. Place further discussion of the library in the official review thread. If replying to an opinion stated during a vote, copy all relevant context and post in the official review thread. If you would like to see the proposed module included into Phobos Vote Yes If one condition must be met Vote Yes explicitly stating it is under a condition and what condition. You may specify an improvement you'd like to see, but be sure to state it is not a condition/showstopper. Otherwise Vote No A brief reason should be provided though details on what needs improvement should be placed in the official review thread.(c) wiki.dlang.org/Review/Process ----------------------------------------------------- If you need to ask any last moment questions before making your decision, please do it in last review thread (linked in beginning of this post). Voting will last until the next weekend (Oct 12 23:59 GMT +0) Thanks for your attention.
Oct 02 2013
Yes. I see this effort driving great advances in D's tooling ecosystem.
Oct 02 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos. ----------------------------------------------------- All relevant information can be found here: http://wiki.dlang.org/Review/std.d.lexer (it includes link to post-review change set and some clarifications by Brian) Review thread is here: http://forum.dlang.org/post/jsnhlcbulwyjuqcqoepe forum.dlang.org ----------------------------------------------------- Instructions for votersYes :)The goal of the vote is to allow the Review Manager to decided if the community agrees on the inclusion of the submission. Place further discussion of the library in the official review thread. If replying to an opinion stated during a vote, copy all relevant context and post in the official review thread. If you would like to see the proposed module included into Phobos Vote Yes If one condition must be met Vote Yes explicitly stating it is under a condition and what condition. You may specify an improvement you'd like to see, but be sure to state it is not a condition/showstopper. Otherwise Vote No A brief reason should be provided though details on what needs improvement should be placed in the official review thread.(c) wiki.dlang.org/Review/Process ----------------------------------------------------- If you need to ask any last moment questions before making your decision, please do it in last review thread (linked in beginning of this post). Voting will last until the next weekend (Oct 12 23:59 GMT +0) Thanks for your attention.
Oct 02 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos. ----------------------------------------------------- All relevant information can be found here: http://wiki.dlang.org/Review/std.d.lexer (it includes link to post-review change set and some clarifications by Brian) Review thread is here: http://forum.dlang.org/post/jsnhlcbulwyjuqcqoepe forum.dlang.org ----------------------------------------------------- Instructions for votersYes.The goal of the vote is to allow the Review Manager to decided if the community agrees on the inclusion of the submission. Place further discussion of the library in the official review thread. If replying to an opinion stated during a vote, copy all relevant context and post in the official review thread. If you would like to see the proposed module included into Phobos Vote Yes If one condition must be met Vote Yes explicitly stating it is under a condition and what condition. You may specify an improvement you'd like to see, but be sure to state it is not a condition/showstopper. Otherwise Vote No A brief reason should be provided though details on what needs improvement should be placed in the official review thread.(c) wiki.dlang.org/Review/Process ----------------------------------------------------- If you need to ask any last moment questions before making your decision, please do it in last review thread (linked in beginning of this post). Voting will last until the next weekend (Oct 12 23:59 GMT +0) Thanks for your attention.
Oct 03 2013
Yes. ( I have not found any rules that prohibit review manager from voting :) )
Oct 03 2013
On Thursday, 3 October 2013 at 11:04:26 UTC, Dicebot wrote:Yes. ( I have not found any rules that prohibit review manager from voting :) )I'd love to say yes, since I've been dreaming of the day when we finally have a lexer... but I decided to put my yes under the condition that it can lex itself using ctfe. My first attempt with adding a "import(__FILE__)" unittest failed with v2.063.2: Error: memcpy cannot be interpreted at compile time, because it has no available source code lexer.d(1966): called from here: move(lex) lexer.d(454): called from here: r.this(lexerSource(range), config) Maybe this is this fixed in HEAD though?
Oct 03 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos. ----------------------------------------------------- [...] Thanks for your attention.Yes. (Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)
Oct 03 2013
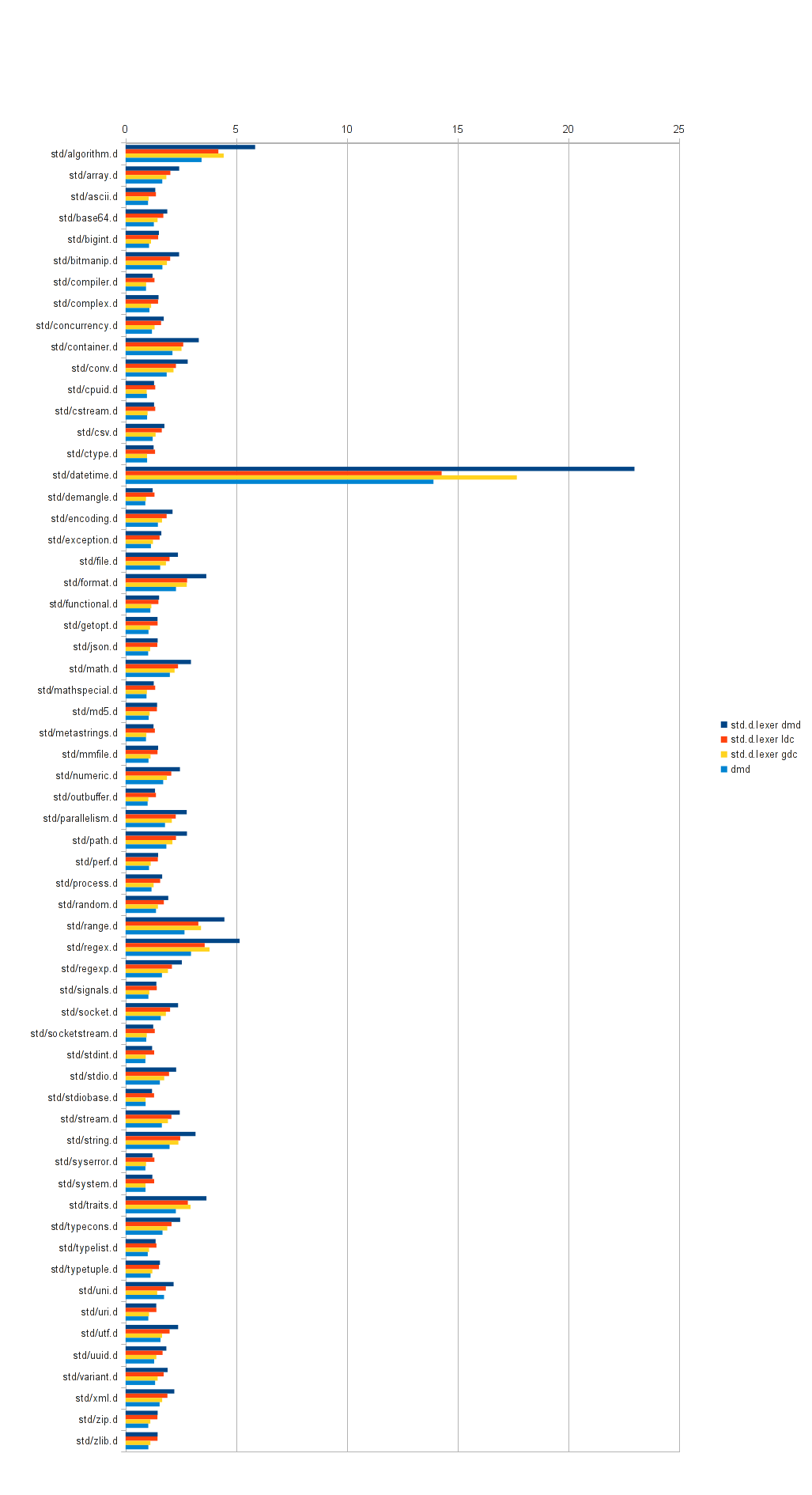
On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:(Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.png They're a bit old at this point, but not much has changed in the lexer internals. I can try running another set of benchmarks soon. (The hardest part is hacking DMD to just do the lexing) The times on the X-axis are milliseconds.
{kind=link}
Oct 03 2013
On 10/3/13 12:47 PM, Brian Schott wrote:On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. Andrei(Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.png They're a bit old at this point, but not much has changed in the lexer internals. I can try running another set of benchmarks soon. (The hardest part is hacking DMD to just do the lexing) The times on the X-axis are milliseconds.
Oct 03 2013
On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:On 10/3/13 12:47 PM, Brian Schott wrote:Considerably? They look very similar to me. dmd is just slightly winning.On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. Andrei(Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.png They're a bit old at this point, but not much has changed in the lexer internals. I can try running another set of benchmarks soon. (The hardest part is hacking DMD to just do the lexing) The times on the X-axis are milliseconds.
Oct 03 2013
On 10/3/13 1:15 PM, Brad Anderson wrote:On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:To me 10% is considerable. AndreiOn 10/3/13 12:47 PM, Brian Schott wrote:Considerably? They look very similar to me. dmd is just slightly winning.On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. Andrei(Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.png They're a bit old at this point, but not much has changed in the lexer internals. I can try running another set of benchmarks soon. (The hardest part is hacking DMD to just do the lexing) The times on the X-axis are milliseconds.
Oct 03 2013
Please express your opinion in a clear "Yes", "No" or "Yes, if" form. I can't really interpret discussions into voting results. Of course, you and Walter also have "veto" votes in addition but it needs to be said explicitly.
Oct 03 2013
On 10/3/13 3:03 PM, Dicebot wrote:Please express your opinion in a clear "Yes", "No" or "Yes, if" form. I can't really interpret discussions into voting results. Of course, you and Walter also have "veto" votes in addition but it needs to be said explicitly.That's why I renamed the thread! I didn't vote. Andrei
Oct 03 2013
On Thursday, 3 October 2013 at 22:18:13 UTC, Andrei Alexandrescu wrote:On 10/3/13 3:03 PM, Dicebot wrote:I mean I will be forced to ignore your opinion in current form when making voting summary and I will feel very uneasy about it :) (damn, that review manager thingy gets much more stressful by the end!)Please express your opinion in a clear "Yes", "No" or "Yes, if" form. I can't really interpret discussions into voting results. Of course, you and Walter also have "veto" votes in addition but it needs to be said explicitly.That's why I renamed the thread! I didn't vote. Andrei
Oct 03 2013
On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:On 10/3/13 12:47 PM, Brian Schott wrote:Quite frankly, I (or better say many of us) need a COMPLETE D lexer that is UP TO DATE. std.lexer should be, if it is a Phobos module, and that is all that matters. Performance optimizations can come later. So what if it's API will change? We, who use D2 since the very beginning, are used to it! API changes can be done smoothly, with phase-out stages. People would be informed what pieces of the API will become deprecated, and it is their responsibility to fix their code to reflect such changes. All that is needed is little bit of planning...On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. Andrei(Btw, someone got benchmarks of std.d.lexer? I remember that Brain was benchmarking his module quite a lot in order to catch up with DMD's lexer but I can't find links in IRC logs. I wonder if he achieved his goal in this regard)The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.png They're a bit old at this point, but not much has changed in the lexer internals. I can try running another set of benchmarks soon. (The hardest part is hacking DMD to just do the lexing) The times on the X-axis are milliseconds.
Oct 04 2013
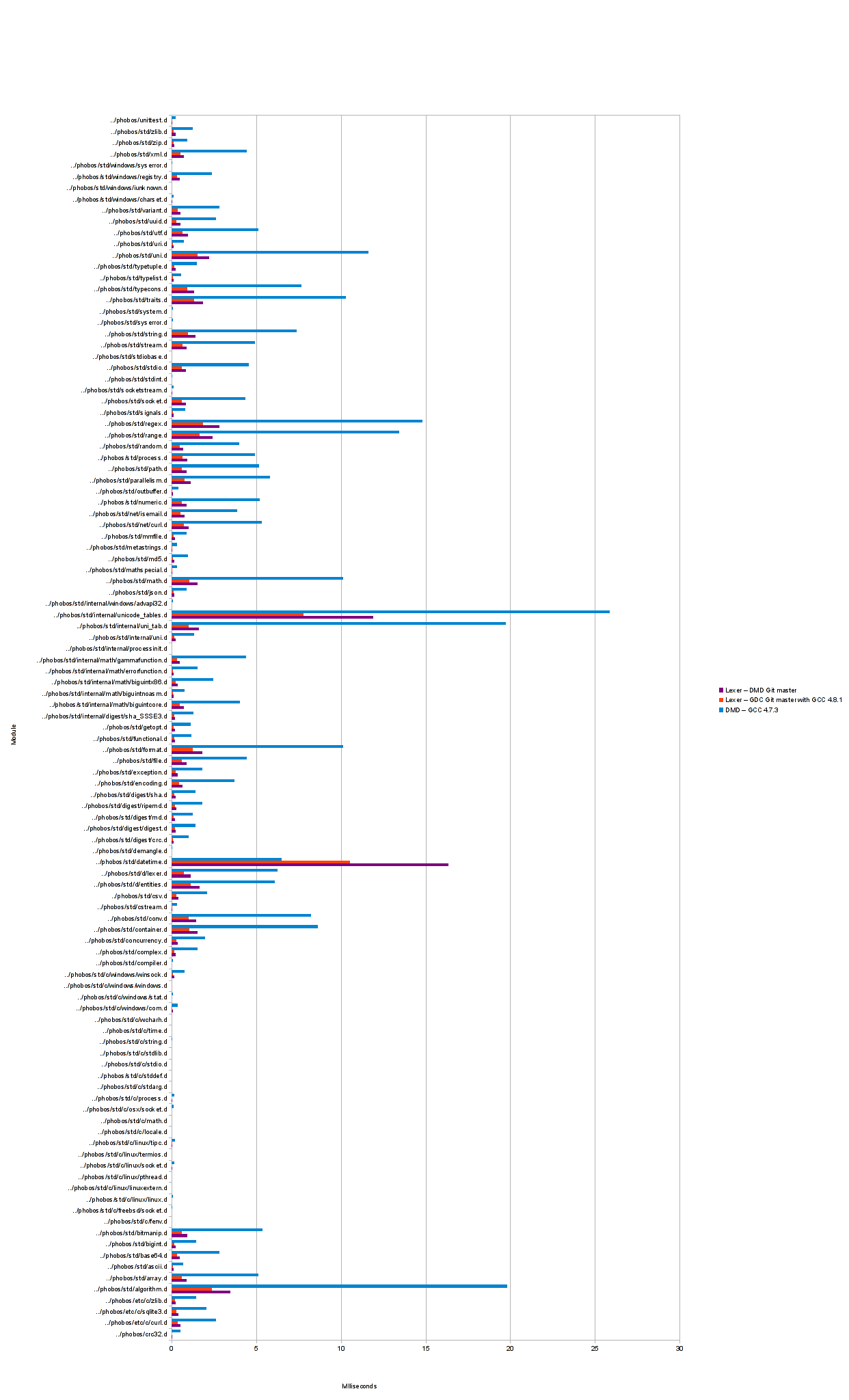
On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. AndreiThe old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark
{kind=link}
Oct 04 2013
On 2013-10-04 13:28, Brian Schott wrote:Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmarkIf these results are correct, me like :) -- /Jacob Carlborg
Oct 04 2013
Brian Schott wrote:On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:Interestingly, DMD is only faster when lexing std.datetime. This is relatively big file, so maybe the slowness is related to small buffering in std.d.lexer?I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. AndreiThe old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark
Oct 04 2013
04-Oct-2013 15:28, Brian Schott пишет:On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); Plus I think clock_gettime often has too coarse resolution (I'd use gettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful. -- Dmitry OlshanskyI see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. AndreiThe old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark
Oct 11 2013
On Friday, October 11, 2013 12:56:14 Dmitry Olshansky wrote:04-Oct-2013 15:28, Brian Schott =D0=BF=D0=B8=D1=88=D0=B5=D1=82:ote:On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wr=dI see we're considerably behind dmd. If improving performance woul=offcome at the price of changing the API, it may be sensible to hold =ofadoption for a bit. =20 Andrei=20 The old benchmarks measured total program run time. I ran a new set=arbenchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a simil=perimenmodification to DMD. =20 Here's the result: =20 https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/ex=chtal/std_lexer/images/times5.png =20 =20 I suspect that I've made an error in the benchmarking due to how mu=faster std.d.lexer is than DMD now, so I've uploaded what I have to=ngful. Why not just use use std.datetime's benchmark or StopWatch? Though look= ing at=20 lexerbenchmark.d it looks like he's using StopWatch rather than clock_g= ettime=20 directly, and there are no printfs, so I don't know what code you're re= ferring=20 to here. From the looks of it though, he's basically reimplemented=20 std.datetime.benchmark in benchmarklexer.d and probably should have jus= t used=20 benchmark instead. - Jonathan M DavisGithub. =20 https://github.com/Hackerpilot/lexerbenchmark=20 I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); =20 Plus I think clock_gettime often has too coarse resolution (I'd use gettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meani=
Oct 11 2013
11-Oct-2013 13:07, Jonathan M Davis пишет:On Friday, October 11, 2013 12:56:14 Dmitry Olshansky wrote:Cause it's C++ damn it! ;)04-Oct-2013 15:28, Brian Schott пишет:Why not just use use std.datetime's benchmark or StopWatch? Though looking at lexerbenchmark.d it looks like he's using StopWatch rather than clock_gettime directly, and there are no printfs, so I don't know what code you're referring to here. From the looks of it though, he's basically reimplemented std.datetime.benchmark in benchmarklexer.d and probably should have just used benchmark instead.On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); Plus I think clock_gettime often has too coarse resolution (I'd use gettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful.I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. AndreiThe old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimen tal/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark- Jonathan M Davis-- Dmitry Olshansky
Oct 11 2013
On Friday, October 11, 2013 13:53:29 Dmitry Olshansky wrote:11-Oct-2013 13:07, Jonathan M Davis =D0=BF=D0=B8=D1=88=D0=B5=D1=82:wrote:On Friday, October 11, 2013 12:56:14 Dmitry Olshansky wrote:04-Oct-2013 15:28, Brian Schott =D0=BF=D0=B8=D1=88=D0=B5=D1=82:On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu =uldI see we're considerably behind dmd. If improving performance wo=d offcome at the price of changing the API, it may be sensible to hol=et ofadoption for a bit. =20 Andrei=20 The old benchmarks measured total program run time. I ran a new s=obenchmarks, placing stopwatch calls around just the lexing code t=ilarbypass any slowness caused by druntime startup. I also made a sim=experimmodification to DMD. =20 Here's the result: =20 https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/=muchen tal/std_lexer/images/times5.png =20 =20 I suspect that I've made an error in the benchmarking due to how =tofaster std.d.lexer is than DMD now, so I've uploaded what I have =eGithub. =20 https://github.com/Hackerpilot/lexerbenchmark=20 I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); =20 Plus I think clock_gettime often has too coarse resolution (I'd us=lookinggettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful.=20 Why not just use use std.datetime's benchmark or StopWatch? Though =hatat lexerbenchmark.d it looks like he's using StopWatch rather than clock_gettime directly, and there are no printfs, so I don't know w=andcode you're referring to here. From the looks of it though, he's basically reimplemented std.datetime.benchmark in benchmarklexer.d =Your comments would make perfect sense for C++, but lexerbenchmark.d is= in D.=20 And I don't know what else you could be talking about, because that's a= ll I=20 see referenced here. - Jonathan M Davisprobably should have just used benchmark instead.=20 Cause it's C++ damn it! ;)
Oct 11 2013
11-Oct-2013 14:58, Jonathan M Davis пишет:On Friday, October 11, 2013 13:53:29 Dmitry Olshansky wrote:I was looking at dmd.diff actually in linked repo. https://github.com/Hackerpilot/lexerbenchmark/blob/master/dmd.diff lexerbenchmark.d uses StopWatch.11-Oct-2013 13:07, Jonathan M Davis пишет:Your comments would make perfect sense for C++, but lexerbenchmark.d is in D. And I don't know what else you could be talking about, because that's all I see referenced here.On Friday, October 11, 2013 12:56:14 Dmitry Olshansky wrote:Cause it's C++ damn it! ;)04-Oct-2013 15:28, Brian Schott пишет:Why not just use use std.datetime's benchmark or StopWatch? Though looking at lexerbenchmark.d it looks like he's using StopWatch rather than clock_gettime directly, and there are no printfs, so I don't know what code you're referring to here. From the looks of it though, he's basically reimplemented std.datetime.benchmark in benchmarklexer.d and probably should have just used benchmark instead.On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); Plus I think clock_gettime often has too coarse resolution (I'd use gettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful.I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. AndreiThe old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experim en tal/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark- Jonathan M Davis-- Dmitry Olshansky
Oct 11 2013
On Thursday, 3 October 2013 at 19:47:28 UTC, Brian Schott wrote:The most recent set of timings that I have can be found here: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times4.pngHow exactly were these figures obtained? Based on the graphs, I'd guess that you measured execution time of a complete program (as LDC, which has a slightly higher startup overhead in druntime, overtakes GDC for larger inputs). If that's the case, DMD might be at an unfair advantage for this benchmark as it doesn't need to run all the druntime startup code – which is not a lot, but still. And indeed, its advantage seems to shrink for large inputs, although I don't want to imply that this could be the only reason. David
Oct 03 2013
On Thursday, 3 October 2013 at 19:07:03 UTC, nazriel wrote:On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote: ...Please keep "btw"s in separate thread :)
Oct 03 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:If you need to ask any last moment questions before making your decision, please do it in last review thread (linked in beginning of this post). Voting will last until the next weekend (Oct 12 23:59 GMT +0) Thanks for your attention.I sadly have to vote no in the current state. It is really needed to be able to reuse the same pool of identifier across several lexing (otherwize tooling around this lexer won't be able to manage mixins properly unless rolling its own identifier pool on top of the lexer's). This require the interface to change, so can't be introduced in a latter version without major breakage. I'd vote yes if above condition is met or to integrate current module as experimental (not in std).
Oct 03 2013
On 10/02/2013 04:41 PM, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.I also have to vote with no for now. My biggest concern is that the lexer incorporates a string pool, something that isn't strictly part of lexing. IMO this is a major design flaw and possible performance/memory issue. It is buried into the API because byToken takes const(byte)[], i.e. mutable data, but each Token carries a string value, so it always requires a copy. For stream oriented lexing, e.g. token highlighting, no string pool is required at all. Instead the value type of Token should be something like take(input.save, lengthOfToken). Why was the Tok!">>=", Tok!"default" idea turned down. This leaves us with undesirable names like Tok.shiftRightAssign, Tok.default_. There are a few smaller issues that haven't yet been addressed, but of course this can be done during the merge code review. Adding it as experimental module would be a good idea.
Oct 03 2013
On 10/04/2013 04:57 AM, Martin Nowak wrote:I also have to vote with no for now.And working in CTFE can't be easily given up either.
Oct 03 2013
On Friday, 4 October 2013 at 02:57:41 UTC, Martin Nowak wrote:Adding it as experimental module would be a good idea.I would be in favor of adding such community-reviewed but not-quite-there-yet libraries to a special category on the DUB registry instead. It would also solve the visibility problem, and apart from the fact that it isn't really clear what being an »experimental« module would entail, having it as a package also allows for faster updates not reliant on the core release schedule. David
Oct 03 2013
I created https://github.com/phobos-x/phobosx for this, it is also in the dub registry.=20 It could be used, until something more official is established. Best regards, Robert On Fri, 2013-10-04 at 05:29 +0200, David Nadlinger wrote:On Friday, 4 October 2013 at 02:57:41 UTC, Martin Nowak wrote:=20Adding it as experimental module would be a good idea.=20 I would be in favor of adding such community-reviewed but=20 not-quite-there-yet libraries to a special category on the DUB=20 registry instead. =20 It would also solve the visibility problem, and apart from the=20 fact that it isn't really clear what being an =C2=BBexperimental=C2=AB=module would entail, having it as a package also allows for=20 faster updates not reliant on the core release schedule. =20 David
Oct 04 2013
Why was the Tok!">>=", Tok!"default" idea turned down. This leaves us with undesirable names like Tok.shiftRightAssign, Tok.default_.Martin, that is truly a matter of taste. I, for an instance, do not like Tok!">>=" - too many special characters there for my taste. To me it looks like some part of a weird Perl script.
Oct 04 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. Let's iron out the issues first, both interface and possible performance issues.
Oct 04 2013
On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. I really want to see `std.d.lexer` in Phobos, but have too many conditions. Documentation issues: - please specify the parser algorithm that you used for `std.d.lexer`. As I understand from review thread, you implement `GLR parser` - please document it (correct me if I wrong). Also, add link to the algorithm description, for example to the wikipedia: http://en.wikipedia.org/wiki/GLR_parser It helps to understand how `std.d.lexer` works. Also, please add best-case and worst-case time complexity (for example, from O(n) to O(n^3)), and best-case and worst-case memory complexity. - please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function. - explicitly specify functions that can throw: add `Throws:` block for it and specify conditions when they can throw. UTF-16/UTF-32 support: - why standart `std.d.lexer` supports only UTF-8, but not a UTF-16/UTF-32? The official lexing specification allows all of them. The conversion from UTF-16/UTF-32 to UTF-8 is not a option due performance issues. If Phobos string functions too slow, please add a bug. If Phobos haven't got necessary functions, please add enhancement request. I think it's serious issue that affects all string utilities (like std.xml or std.json), not only `std.d.lexer`. Exception handling - please use `ParseException` as a default exception, not the `Exception`. Codestyle: - I don't like `TokenType` enum. You can use Tok!">>=" and `static if` to compare the token string to the `TokenType` enum. So, you will not lose performance, because string parsing will be done at compile time. Not a condition, but wishlist: - implement low-level API, not only high-level range-based API. I hope it can help increase performance for applications that really need it. - add ability to use `std.d.lexer` at the compile time.
Oct 04 2013
On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:clipAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. I really want to see `std.d.lexer` in Phobos, but have too many conditions. Documentation issues:- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
Oct 04 2013
On Friday, 4 October 2013 at 14:30:12 UTC, Craig Dillabaugh wrote:On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:I said: "TRY to add". But yes, I feel that `std.d.lexer` don't have enough documentation.On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:clipAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. I really want to see `std.d.lexer` in Phobos, but have too many conditions. Documentation issues:- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
Oct 04 2013
On Friday, 4 October 2013 at 16:03:25 UTC, ilya-stromberg wrote:On Friday, 4 October 2013 at 14:30:12 UTC, Craig Dillabaugh wrote:I think it was a good idea ... it just sort of jumped out at me as the Phobos documentation tends to be missing lots of examples. Thus the smiley on the end.On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:I said: "TRY to add". But yes, I feel that `std.d.lexer` don't have enough documentation.On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:clipAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. I really want to see `std.d.lexer` in Phobos, but have too many conditions. Documentation issues:- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
Oct 04 2013
On Fri, Oct 04, 2013 at 04:30:11PM +0200, Craig Dillabaugh wrote:On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:[...]The rest of Phobos docs *should* be put to shame. Except maybe for a few exceptions here and there, most of Phobos docs are far too scant, and need some serious TLC with many many more code examples. T -- Customer support: the art of getting your clients to pay for your own incompetence.- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
Oct 04 2013
On 10/4/13 7:30 AM, Craig Dillabaugh wrote:On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:I would say matters that are passable for now and easy to improve later without disruption don't necessarily preclude approval. AndreiOn Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:clipAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.No. I really want to see `std.d.lexer` in Phobos, but have too many conditions. Documentation issues:- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
Oct 04 2013
On 10/2/13 7:41 AM, Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. But there's plenty of good news. 1. I am not attempting to veto this, so just consider it a normal vote when tallying. 2. I do vote for inclusion in the /etc/ package for the time being. 3. The work is good and the code valuable, so even in the case my suggestions (below) will be followed, a virtually all code pulp that gets work done can be reused. Vision ====== I'd been following the related discussions for a while, but I have made up my mind today as I was working on a C++ lexer today. The C++ lexer is for Facebook's internal linter. I'm translating the lexer from C++. Before long I realized two simple things. First, I can't reuse anything from Brian's code (without copying it and doing surgery on it), although it is extremely similar to what I'm doing. Second, I figured that it is almost trivial to implement a simple, generic, and reusable (across languages and tasks) static trie searcher that takes a compile-time array with all tokens and keywords and returns the token at the front of a range with minimum comparisons. Such a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind. The beauty of it all is that all of these more involved bits (many of which are language specific) can be implemented modularly and trivially as a postprocessing step after the trie finder. For example the user specifies "/*" as a token to the trie finder. Whenever a comment starts, the trie finder will find and return it; then the user implements the alternate grammar of multiline comments. To encode the tokens returned by the trie, we must do away with definitions such as enum TokenType : ushort { invalid, assign, ... } These are fine for a tokenizer written in C, but are needless duplication from a D perspective. I think a better approach is: struct TokenType { string symbol; ... } TokenType tok(string s)() { static immutable string interned = s; return TokenType(interned); } Instead of associating token types with small integers, we associate them with string addresses. (For efficiency we may use pointers to zero-terminated strings, but I don't think that's necessary). Token types are interned by design, i.e. to compare two tokens for equality it suffices to compare the strings with "is" (this can be extended to general identifiers, not only statically-known tokens). Then, each token type has a natural representation that doesn't require the user to remember the name of the token. The left shift token is simply tok!"<<" and is application-global. The static trie finder does not even build a trie - it simply generates a bunch of switch statements. The signature I've used is: Tuple!(size_t, size_t, Token) staticTrieFinder(alias TokenTable, R)(R r) { It returns a tuple with (a) whitespace characters before token, (b) newlines before token, and (c) the token itself, returned as tok!"whatever". To use for C++: alias CppTokenTable = TypeTuple!( "~", "(", ")", "[", "]", "{", "}", ";", ",", "?", "<", "<<", "<<=", "<=", ">", ">>", ">>=", "%", "%=", "=", "==", "!", "!=", "^", "^=", "*", "*=", ":", "::", "+", "++", "+=", "&", "&&", "&=", "|", "||", "|=", "-", "--", "-=", "->", "->*", "/", "/=", "//", "/*", "\\", ".", "'", "\"", "and", "and_eq", "asm", "auto", ... ); Then the code uses staticTrieFinder!([CppTokenTable])(range). Of course, it's also possible to define the table itself as an array. I'm exploring right now in search for the most advantageous choices. I think the above would be a true lexer in the D spirit: - exploits D's string templates to essentially define non-alphanumeric symbols that are easy to use and understand, not confined to predefined tables (that enum!) and cheap to compare; - exploits D's code generation abilities to generate really fast code using inlined trie searching; - offers and API that is generic, flexible, and infinitely reusable. If what we need at this point is a conventional lexer for the D language, std.d.lexer is the ticket. But I think it wouldn't be difficult to push our ambitions way beyond that. What say you? Andrei
Oct 04 2013
On Saturday, 5 October 2013 at 00:24:22 UTC, Andrei Alexandrescu wrote:Vision ====== I'd been following the related discussions for a while, but I have made up my mind today as I was working on a C++ lexer today. The C++ lexer is for Facebook's internal linter. I'm translating the lexer from C++. Before long I realized two simple things. First, I can't reuse anything from Brian's code (without copying it and doing surgery on it), although it is extremely similar to what I'm doing. Second, I figured that it is almost trivial to implement a simple, generic, and reusable (across languages and tasks) static trie searcher that takes a compile-time array with all tokens and keywords and returns the token at the front of a range with minimum comparisons. Such a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind. The beauty of it all is that all of these more involved bits (many of which are language specific) can be implemented modularly and trivially as a postprocessing step after the trie finder. For example the user specifies "/*" as a token to the trie finder. Whenever a comment starts, the trie finder will find and return it; then the user implements the alternate grammar of multiline comments.That is more or less how SDC's lexer works. You pass it 2AA : one with string associated with tokens type, and one with string to function's name that return the actual token (for instance to handle /*) and finally one when nothing matches. A giant 3 headed monster mixin is created from these data. That has been really handy so far.If what we need at this point is a conventional lexer for the D language, std.d.lexer is the ticket. But I think it wouldn't be difficult to push our ambitions way beyond that. What say you?Yup, I do agree.
Oct 04 2013
On 10/4/2013 5:24 PM, Andrei Alexandrescu wrote:Such a trie searcher is not intelligent, but is very composable and extremely fast.Well, boys, I reckon this is it — benchmark combat toe to toe with the cooders. Now look, boys, I ain't much of a hand at makin' speeches, but I got a pretty fair idea that something doggone important is goin' on around there. And I got a fair idea the kinda personal emotions that some of you fellas may be thinkin'. Heck, I reckon you wouldn't even be human bein's if you didn't have some pretty strong personal feelin's about benchmark combat. I want you to remember one thing, the folks back home is a-countin' on you and by golly, we ain't about to let 'em down. I tell you something else, if this thing turns out to be half as important as I figure it just might be, I'd say that you're all in line for some important promotions and personal citations when this thing's over with. That goes for ever' last one of you regardless of your race, color or your creed. Now let's get this thing on the hump - we got some benchmarkin' to do.
Oct 04 2013
On 2013-10-05 02:24, Andrei Alexandrescu wrote:Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. [Snip]Is this something in the middle of a hand written lexer and a lexer automatically generated? I think we can have both. A hand written lexer, specifically targeted for D that is very fast. Then a more general lexer that can be used for many languages. I have to say I think this is a bit unfair to dump this huge thing in the voting thread. You haven't made a single post in the discussion thread and now you're coming with this big suggestions in the voting thread. -- /Jacob Carlborg
Oct 05 2013
On 10/05/13 13:45, Jacob Carlborg wrote:I think we can have both. A hand written lexer, specifically targeted for D that is very fast. Then a more general lexer that can be used for many languages.The assumption, that a hand-written lexer will be much faster than a generated one, is wrong. If there's any significant perf difference then it's just a matter of improving the generator. An automatically generated lexer will be much more flexible (the source spec can be reused without a single modification for anything from an intelligent LOC-like counter or a syntax highlighter to a compiler), easier to maintain/review and less buggy. Compare the perf numbers previously posted here for the various lexers with: $ time ./tokenstats stats std/datetime.d Lexed 1589336 bytes, found 461315 tokens, 13770 keywords, 65946 identifiers. Comments: Line: 958 ~40.16 Block: 1 ~16 Nesting: 534 ~441.7 [count avg_len] 0m0.010s user 0m0.001s system 0m0.011s elapsed 99.61% CPU $ time ./tokenstats dump-no-io std/datetime.d 0m0.013s user 0m0.001s system 0m0.014s elapsed 99.78% CPU 'tokenstats' is built from PEG-like spec plus a bit CT magic. The generator supports inline rules written in D too, but the only ones actually written in D are for defining what an identifier is, matching EOLs and handling DelimitedStrings. Initially, performance was not a consideration at all and there's some very low hanging fruit in there; there's still room for improvement. Unfortunately, the language and compiler situation has prevented me from doing any work on this for the last half year or so. The code won't work with any current compiler and needs a lot of cleanups (which I have been planning to do /after/ updating the tooling, which seems very unlikely to be possible now), hence it's not in a releasable state. [1] artur [1] If anyone wants to play with it, use as a reference etc and isn't afraid of running a binary, a linux x86 one can be gotten from http://d-h.st/xtX The only really useful functionality is 'tokenstats dump file.d', which will dump all found tokens with line and columns numbers. It's just a tool i've been using for identifying regressions and benching.
Oct 05 2013
On 2013-10-05 19:52, Artur Skawina wrote:The assumption, that a hand-written lexer will be much faster than a generated one, is wrong.I never said that the generated one would be slow. I only said that the hand written would be fast :) -- /Jacob Carlborg
Oct 06 2013
On 10/06/13 10:57, Jacob Carlborg wrote:On 2013-10-05 19:52, Artur Skawina wrote:I know, but you said that having both is an option -- that would not make sense unless there's a significant advantage. A lexer is really a rather trivial piece of software, there's not much room for improvement over the obvious "fetch-a-character, use-it-to- determine-a-new-state, repeat-until-done, return the found state ( == matched token)" approach. So the core of an efficient hand-written lexer will not be very different from this: http://repo.or.cz/w/girtod.git/blob/refs/heads/lexer:/mainloop.d That is already ~2kLOC and it's *just* the top-level loop; it does not include handling of nontrivial tokens (matches just keywords, punctuators and identifiers). Could a handwritten lexer be faster? Not by much, and any trick that would help the manually-written one could also be used by the generator. In fact, working on the generator is much easier than dealing with this kind of fragile hand-tuned mess. Imagine changing the lexical grammar a bit, or introducing a new kind of literal. With a more declarative solution this only involves a local change spanning a few lines and is relatively risk-free. Updating a handwritten lexer would involve many more changes, often in several different areas, and lots of opportunities for making mistakes.The assumption, that a hand-written lexer will be much faster than a generated one, is wrong.I never said that the generated one would be slow. I only said that the hand written would be fast :)Would it be able to lex Scala and Ruby? Method names in Scala can contain many symbols that is not usually allowed in other languages. You can have a method named "==". In Ruby method names are allowed to end with "=", "?" or "!".Yes, D makes it easy, you can for example simply define a function that determines what is and what isn't an identifier and pass that as an alias or mixin parameter. "Lexing" binary formats would be possible too :^). A complete D lexer can look as simple as this: http://repo.or.cz/w/girtod.git/blob/refs/heads/lexer:/dlanglexer.d which should also give you a good idea of how easy supporting other languages would be. (The "actions" are defined in separate modules, so that the grammars can be reused everywhere). There's a D PEG lexical grammar in there too, btw. I forgot to change the subject previously, sorry; was not trying to attempt or influence the voting. I'm just saying that Andrei's approach goes into the right direction (even if i disagree with the details). And IMHO the time before a useful std-lib-worthy lexer infrastructure materializes is measured in months, if not years. So if I was voting I'd probably say "yes" - because waiting for a better, but non-existent alternative is not going to help anybody. The hard part of the required work isn't coding - it's the design. If a better solution appears later, it should be able to /replace/ the hand-written one. And in the mean time, the experience from using the less-generic lexer can only help any "new" design. artur
Oct 07 2013
Jacob Carlborg <doob me.com> wrote:On 2013-10-05 02:24, Andrei Alexandrescu wrote:I don't understand this question.Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. [Snip]Is this something in the middle of a hand written lexer and a lexer automatically generated?I think we can have both. A hand written lexer, specifically targeted for D that is very fast. Then a more general lexer that can be used for many languages.I agree with Artur that this is a fallacy.I have to say I think this is a bit unfair to dump this huge thing in the voting thread. You haven't made a single post in the discussion thread and now you're coming with this big suggestions in the voting thread.The way I see it it's unfair of you to claim that. All I did was to vote and to explain that vote. I was very explicit I don't want to pull rank or anything. Besides it was an idea and such things are hard to time. I think std.d.lexer is a fine product that works as advertised. But I also believe very strongly that it doesn't exploit D's advantages and that adopting it would lock us into a suboptimal API. I have strengthened this opinion only since yesterday morning. Andrei
Oct 05 2013
On 2013-10-05 20:45, Andrei Alexandrescu wrote:I don't understand this question.I never said that the generated one would be slow. I only said that the hand written would be fast :)I think we can have both. A hand written lexer, specifically targeted for D that is very fast. Then a more general lexer that can be used for many languages.I agree with Artur that this is a fallacy.I just think that if you were not completely satisfied with the current API or implementation you could have said so in the discussion thread. It would have at least given Brian a chance to do something about it, before the voting began. -- /Jacob CarlborgI have to say I think this is a bit unfair to dump this huge thing in the voting thread. You haven't made a single post in the discussion thread and now you're coming with this big suggestions in the voting thread.The way I see it it's unfair of you to claim that. All I did was to vote and to explain that vote. I was very explicit I don't want to pull rank or anything. Besides it was an idea and such things are hard to time. I think std.d.lexer is a fine product that works as advertised. But I also believe very strongly that it doesn't exploit D's advantages and that adopting it would lock us into a suboptimal API. I have strengthened this opinion only since yesterday morning.
Oct 06 2013
On Sunday, 6 October 2013 at 08:59:57 UTC, Jacob Carlborg wrote:I just think that if you were not completely satisfied with the current API or implementation you could have said so in the discussion thread. It would have at least given Brian a chance to do something about it, before the voting began.Maybe we went to the voting too fast, and somebody had not enough time to read documentation and write a opinion? Maybe we should wait at least 1-2 weeks from last review before start a new voting? Maybe we should announce upcoming voting for one week prior to start a new voting thread? I belive that it pays additional attention to the new module and helps avoid situations like this.
Oct 06 2013
On Sunday, 6 October 2013 at 09:37:18 UTC, ilya-stromberg wrote:Maybe we should wait at least 1-2 weeks from last review before start a new voting? Maybe we should announce upcoming voting for one week prior to start a new voting thread? I belive that it pays additional attention to the new module and helps avoid situations like this.There were more than 1 week of time between last comment in review thread and start of voting. If you needed more time for review, you should have mentioned it. In current situation I simply have waited until Brian makes post-review changes he personally wanted and moved forward as it was pretty clear no further input is incoming. Any formal review may potentially result in short voting after if no critical issues are found so I don't think it makes sense in making any additional announcements. There are no special points of attention - if review was declared and you want to make some input, it should be done right there. Of course, review process is as much community-defined as anything else here. You can always define an alternative one and propose it for discussion. Right now though I am sticking to one mentioned in wiki + some of personal common sense for undefined parts (because I am lazy :)). Also you can lend a helping hand and manage next review on your own in a way you find reasonable :P
Oct 06 2013
On Sunday, 6 October 2013 at 18:54:55 UTC, Dicebot wrote:Any formal review may potentially result in short voting after if no critical issues are found so I don't think it makes sense in making any additional announcements. There are no special points of attention - if review was declared and you want to make some input, it should be done right there.Yes, but people are lazy. I don't talk about all of us, but most of people are lazy. Somebody of us will vote because it's interesting, but will not read/write review tread because it requests a time. So, additional announce of upcoming voting can help: "Guys, if you want to vote, it's time to read documentation and write your really cool idea before voting".
Oct 07 2013
On Monday, 7 October 2013 at 13:29:30 UTC, ilya-stromberg wrote:On Sunday, 6 October 2013 at 18:54:55 UTC, Dicebot wrote:This is the reason I've not cast any votes for standard modules - I haven't had the time, or don't have the competence, to cast a valid vote. It would be like voting for a political party without knowing where all parties stands in all cases.Any formal review may potentially result in short voting after if no critical issues are found so I don't think it makes sense in making any additional announcements. There are no special points of attention - if review was declared and you want to make some input, it should be done right there.Yes, but people are lazy. I don't talk about all of us, but most of people are lazy. Somebody of us will vote because it's interesting, but will not read/write review tread because it requests a time. So, additional announce of upcoming voting can help: "Guys, if you want to vote, it's time to read documentation and write your really cool idea before voting".
Oct 07 2013
On Monday, October 07, 2013 17:47:27 simendsjo wrote:On Monday, 7 October 2013 at 13:29:30 UTC, ilya-stromberg wrote:So, it would be like your typical political vote then. ;) - Jonathan m DavisOn Sunday, 6 October 2013 at 18:54:55 UTC, Dicebot wrote:This is the reason I've not cast any votes for standard modules - I haven't had the time, or don't have the competence, to cast a valid vote. It would be like voting for a political party without knowing where all parties stands in all cases.Any formal review may potentially result in short voting after if no critical issues are found so I don't think it makes sense in making any additional announcements. There are no special points of attention - if review was declared and you want to make some input, it should be done right there.Yes, but people are lazy. I don't talk about all of us, but most of people are lazy. Somebody of us will vote because it's interesting, but will not read/write review tread because it requests a time. So, additional announce of upcoming voting can help: "Guys, if you want to vote, it's time to read documentation and write your really cool idea before voting".
Oct 07 2013
On 10/6/13 1:59 AM, Jacob Carlborg wrote:I've always thought we must invest effort into generic lexers and parsers as opposed to ones for dedicated languages, and I have said so several times, most strongly in http://forum.dlang.org/thread/jii1gk$76s$1 digitalmars.com. When discussion and voting had started, I had acquiesced to not interfere because I thought I shouldn't discuss a working design against a hypothetical one. *That* would have been unfair. But now that such a design exists, I think it's fair to bring it up. AndreiI think std.d.lexer is a fine product that works as advertised. But I also believe very strongly that it doesn't exploit D's advantages and that adopting it would lock us into a suboptimal API. I have strengthened this opinion only since yesterday morning.I just think that if you were not completely satisfied with the current API or implementation you could have said so in the discussion thread. It would have at least given Brian a chance to do something about it, before the voting began.
Oct 06 2013
On Saturday, 5 October 2013 at 11:45:47 UTC, Jacob Carlborg wrote:On 2013-10-05 02:24, Andrei Alexandrescu wrote:I asked the same question about support any grammar, not only D grammar, but Brian did not respond: http://forum.dlang.org/post/itlyubosepuqcchhuwdh forum.dlang.orgThanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. [Snip]Is this something in the middle of a hand written lexer and a lexer automatically generated? I think we can have both. A hand written lexer, specifically targeted for D that is very fast. Then a more general lexer that can be used for many languages. I have to say I think this is a bit unfair to dump this huge thing in the voting thread. You haven't made a single post in the discussion thread and now you're coming with this big suggestions in the voting thread.
Oct 05 2013
On 2013-10-05 02:24, Andrei Alexandrescu wrote:Such a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind.Would it be able to lex Scala and Ruby? Method names in Scala can contain many symbols that is not usually allowed in other languages. You can have a method named "==". In Ruby method names are allowed to end with "=", "?" or "!". -- /Jacob Carlborg
Oct 06 2013
On 10/6/13 2:10 AM, Jacob Carlborg wrote:On 2013-10-05 02:24, Andrei Alexandrescu wrote:Yes, easily. Have the trie matcher stop upon whatever symbol it detects and then handle the tail with Ruby-specific code. AndreiSuch a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind.Would it be able to lex Scala and Ruby? Method names in Scala can contain many symbols that is not usually allowed in other languages. You can have a method named "==". In Ruby method names are allowed to end with "=", "?" or "!".
Oct 06 2013
Am 05.10.2013 02:24, schrieb Andrei Alexandrescu:Instead of associating token types with small integers, we associate them with string addresses. (For efficiency we may use pointers to zero-terminated strings, but I don't think that's necessary).would it be also more efficent to generate a big string out of the token list containing all tokes concatenated and use a generated string-slice for the associated string accesses? imutable string generated_flat_token_stream = "...publicprivateclass..." "public" = generated_flat_token_stream[3..9] or would that kill caching on todays machines?
Oct 06 2013
On Saturday, 5 October 2013 at 00:24:22 UTC, Andrei Alexandrescu wrote:On 10/2/13 7:41 AM, Dicebot wrote:How quickly do you think this vision could be realized? If soon, I'd say it's worth delaying a decision on the current proposed lexer, if not ... well, jam tomorrow, perfect is the enemy of good, and all that ...After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. But there's plenty of good news. 1. I am not attempting to veto this, so just consider it a normal vote when tallying. 2. I do vote for inclusion in the /etc/ package for the time being. 3. The work is good and the code valuable, so even in the case my suggestions (below) will be followed, a virtually all code pulp that gets work done can be reused. Vision ====== I'd been following the related discussions for a while, but I have made up my mind today as I was working on a C++ lexer today. The C++ lexer is for Facebook's internal linter. I'm translating the lexer from C++. Before long I realized two simple things. First, I can't reuse anything from Brian's code (without copying it and doing surgery on it), although it is extremely similar to what I'm doing. Second, I figured that it is almost trivial to implement a simple, generic, and reusable (across languages and tasks) static trie searcher that takes a compile-time array with all tokens and keywords and returns the token at the front of a range with minimum comparisons. Such a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind. The beauty of it all is that all of these more involved bits (many of which are language specific) can be implemented modularly and trivially as a postprocessing step after the trie finder. For example the user specifies "/*" as a token to the trie finder. Whenever a comment starts, the trie finder will find and return it; then the user implements the alternate grammar of multiline comments. To encode the tokens returned by the trie, we must do away with definitions such as enum TokenType : ushort { invalid, assign, ... } These are fine for a tokenizer written in C, but are needless duplication from a D perspective. I think a better approach is: struct TokenType { string symbol; ... } TokenType tok(string s)() { static immutable string interned = s; return TokenType(interned); } Instead of associating token types with small integers, we associate them with string addresses. (For efficiency we may use pointers to zero-terminated strings, but I don't think that's necessary). Token types are interned by design, i.e. to compare two tokens for equality it suffices to compare the strings with "is" (this can be extended to general identifiers, not only statically-known tokens). Then, each token type has a natural representation that doesn't require the user to remember the name of the token. The left shift token is simply tok!"<<" and is application-global. The static trie finder does not even build a trie - it simply generates a bunch of switch statements. The signature I've used is: Tuple!(size_t, size_t, Token) staticTrieFinder(alias TokenTable, R)(R r) { It returns a tuple with (a) whitespace characters before token, (b) newlines before token, and (c) the token itself, returned as tok!"whatever". To use for C++: alias CppTokenTable = TypeTuple!( "~", "(", ")", "[", "]", "{", "}", ";", ",", "?", "<", "<<", "<<=", "<=", ">", ">>", ">>=", "%", "%=", "=", "==", "!", "!=", "^", "^=", "*", "*=", ":", "::", "+", "++", "+=", "&", "&&", "&=", "|", "||", "|=", "-", "--", "-=", "->", "->*", "/", "/=", "//", "/*", "\\", ".", "'", "\"", "and", "and_eq", "asm", "auto", ... ); Then the code uses staticTrieFinder!([CppTokenTable])(range). Of course, it's also possible to define the table itself as an array. I'm exploring right now in search for the most advantageous choices. I think the above would be a true lexer in the D spirit: - exploits D's string templates to essentially define non-alphanumeric symbols that are easy to use and understand, not confined to predefined tables (that enum!) and cheap to compare; - exploits D's code generation abilities to generate really fast code using inlined trie searching; - offers and API that is generic, flexible, and infinitely reusable. If what we need at this point is a conventional lexer for the D language, std.d.lexer is the ticket. But I think it wouldn't be difficult to push our ambitions way beyond that. What say you?
Oct 06 2013
On 10/6/13 5:40 AM, Joseph Rushton Wakeling wrote:How quickly do you think this vision could be realized? If soon, I'd say it's worth delaying a decision on the current proposed lexer, if not ... well, jam tomorrow, perfect is the enemy of good, and all that ...I'm working on related code, and got all the way there in one day (Friday) with a C++ tokenizer for linting purposes (doesn't open #includes or expand #defines etc; it wasn't meant to). The core generated fragment that does the matching is at https://dpaste.de/GZY3. The surrounding switch statement (also in library code) handles whitespace and line counting. The client code needs to handle by hand things like parsing numbers (note how the matcher stops upon the first digit), identifiers, comments (matcher stops upon detecting "//" or "/*") etc. Such things can be achieved with hand-written code (as I do), other similar tokenizers, DFAs, etc. The point is that the core loop that looks at every character looking for a lexeme is fast. Andrei
Oct 06 2013
On 06/10/13 18:07, Andrei Alexandrescu wrote:I'm working on related code, and got all the way there in one day (Friday) with a C++ tokenizer for linting purposes (doesn't open #includes or expand #defines etc; it wasn't meant to). The core generated fragment that does the matching is at https://dpaste.de/GZY3. The surrounding switch statement (also in library code) handles whitespace and line counting. The client code needs to handle by hand things like parsing numbers (note how the matcher stops upon the first digit), identifiers, comments (matcher stops upon detecting "//" or "/*") etc. Such things can be achieved with hand-written code (as I do), other similar tokenizers, DFAs, etc. The point is that the core loop that looks at every character looking for a lexeme is fast.What I'm getting at is that I'd be prepared to give a vote "no to std, yes to etc" for Brian's d.lexer, _if_ I was reasonably certain that we'd see an alternative lexer module submitted to Phobos within the next month :-)
Oct 06 2013
06-Oct-2013 20:07, Andrei Alexandrescu пишет:On 10/6/13 5:40 AM, Joseph Rushton Wakeling wrote:This is something I agree with. I'd call that loop the "dispatcher loop" in a sense that it detects the kind of stuff and forwards to a special hot loop for that case (if any, e.g. skipping comments). BTW it absolutely must be able to do so in one step, the generated code already knows that the token is tok!"//" hence it may call proper handler right there. case '/': ... switch(s[1]){ ... case '/': // it's a pseudo token anyway so instead of //t = tok!"//"; // just _handle_ it! t = hookFor!"//"(); //user hook for pseudo-token // eats whitespace & returns tok!"comment" or some such // if need be break token_scan; } This also helps to get not only "raw" tokens but allow user to cook extra tokens by hand for special cases that can't be handled by "dispatcher loop".How quickly do you think this vision could be realized? If soon, I'd say it's worth delaying a decision on the current proposed lexer, if not ... well, jam tomorrow, perfect is the enemy of good, and all that ...I'm working on related code, and got all the way there in one day (Friday) with a C++ tokenizer for linting purposes (doesn't open #includes or expand #defines etc; it wasn't meant to). The core generated fragment that does the matching is at https://dpaste.de/GZY3. The surrounding switch statement (also in library code) handles whitespace and line counting. The client code needs to handle by hand things like parsing numbers (note how the matcher stops upon the first digit), identifiers, comments (matcher stops upon detecting "//" or "/*") etc. Such things can be achieved with hand-written code (as I do), other similar tokenizers, DFAs, etc. The point is that the core loop that looks at every character looking for a lexeme is fast.Andrei-- Dmitry Olshansky
Oct 11 2013
On 10/11/13 2:17 AM, Dmitry Olshansky wrote:06-Oct-2013 20:07, Andrei Alexandrescu пишет:That's a good idea. The only concerns I have are: * I'm biased toward patterns for laying efficient code, having hacked into such for the past year. Even discounting for that, I have the feeling that speed is near the top of the list of people who evaluate lexer generators. I fear that too much inline code present inside a fairly large switch statement may hurt efficiency, which is why I'm biased in favor of "small core loop dispatching upon the first few characters, out-of-line code for handling particular cases that need attention". * I've grown to be a big fan of the simplicity of the generator. Yes, that also means bare on features but it's simple enough to be used casually for the simplest tasks that people wouldn't normally think of using a lexer for. If we add hookFor, it would be great if it didn't impact simplicity a lot. AndreiOn 10/6/13 5:40 AM, Joseph Rushton Wakeling wrote:This is something I agree with. I'd call that loop the "dispatcher loop" in a sense that it detects the kind of stuff and forwards to a special hot loop for that case (if any, e.g. skipping comments). BTW it absolutely must be able to do so in one step, the generated code already knows that the token is tok!"//" hence it may call proper handler right there. case '/': ... switch(s[1]){ ... case '/': // it's a pseudo token anyway so instead of //t = tok!"//"; // just _handle_ it! t = hookFor!"//"(); //user hook for pseudo-token // eats whitespace & returns tok!"comment" or some such // if need be break token_scan; } This also helps to get not only "raw" tokens but allow user to cook extra tokens by hand for special cases that can't be handled by "dispatcher loop".How quickly do you think this vision could be realized? If soon, I'd say it's worth delaying a decision on the current proposed lexer, if not ... well, jam tomorrow, perfect is the enemy of good, and all that ...I'm working on related code, and got all the way there in one day (Friday) with a C++ tokenizer for linting purposes (doesn't open #includes or expand #defines etc; it wasn't meant to). The core generated fragment that does the matching is at https://dpaste.de/GZY3. The surrounding switch statement (also in library code) handles whitespace and line counting. The client code needs to handle by hand things like parsing numbers (note how the matcher stops upon the first digit), identifiers, comments (matcher stops upon detecting "//" or "/*") etc. Such things can be achieved with hand-written code (as I do), other similar tokenizers, DFAs, etc. The point is that the core loop that looks at every character looking for a lexeme is fast.
Oct 11 2013
On Saturday, 5 October 2013 at 00:24:22 UTC, Andrei Alexandrescu wrote:2. I do vote for inclusion in the /etc/ package for the time being.What is your vision for the future of etc.*, assuming that we are also going to promote DUB (or another package manager) to "official" status soon as well? Personally, I always found etc.* to be on some strange middle ground between official and non-official – Can I expect these modules to stay around for a longer amount of time? Keep API compatibility according to Phobos policies? The fact that e.g. the libcurl C API modules are also in there makes it seem like a grab-bag of random stuff we didn't quite want to put anywhere else, at least to me. The docs aren't really helpful either: »Modules in etc are not standard D modules. They are here because they are experimental, or for some other reason are not quite suitable for std, although they are still useful.« David
Oct 06 2013
On 06/10/13 18:57, David Nadlinger wrote:The docs aren't really helpful either: »Modules in etc are not standard D modules. They are here because they are experimental, or for some other reason are not quite suitable for std, although they are still useful.«I actually realized I had no idea about what etc was until the last couple of days, and then I thought -- isn't this really what has just been discussed under the proposed name of stdx? ... and if so, why isn't it being used?
Oct 06 2013
On Sunday, 6 October 2013 at 17:08:25 UTC, Joseph Rushton Wakeling wrote:isn't this really what has just been discussed under the proposed name of stdx? ... and if so, why isn't it being used?This is exactly why I'm not too thrilled to make another attempt at establishing something like that. ;) David
Oct 06 2013
On 10/6/13 10:10 AM, David Nadlinger wrote:On Sunday, 6 October 2013 at 17:08:25 UTC, Joseph Rushton Wakeling wrote:We could improve things on our end by featuring etc documentation more prominently etc. I don't think there's a need to reboot things with stdx. Just improve etc. Andreiisn't this really what has just been discussed under the proposed name of stdx? ... and if so, why isn't it being used?This is exactly why I'm not too thrilled to make another attempt at establishing something like that. ;)
Oct 06 2013
On 10/6/13 1:41 PM, Andrei Alexandrescu wrote:On 10/6/13 10:10 AM, David Nadlinger wrote:I'm largely staying out of this conversation, but there's one area that I think is pretty important, speed of development. By having a less official, more readily committable to, repository it stands to reason that it'll evolve faster and fluidly than the phobos code base docs or should. Some of it is just that phobos pull requests lanquish too long, but that's not ALL it is. The bar should be different, not that phobos' bar should be lower. My 2 cents, BradOn Sunday, 6 October 2013 at 17:08:25 UTC, Joseph Rushton Wakeling wrote:We could improve things on our end by featuring etc documentation more prominently etc. I don't think there's a need to reboot things with stdx. Just improve etc. Andreiisn't this really what has just been discussed under the proposed name of stdx? ... and if so, why isn't it being used?This is exactly why I'm not too thrilled to make another attempt at establishing something like that. ;)
Oct 06 2013
On Sunday, 6 October 2013 at 21:32:25 UTC, Brad Roberts wrote:On 10/6/13 1:41 PM, Andrei Alexandrescu wrote:This. The very point of such category is to provide more flexible and still officially approved source for not-yet-there modules. Whatever the reason is that prevents it from straightforward inclusion, it is likely to be reason for plenty of commits to the module. Limiting its polishing to Phobos release model hinders core rationale for having such semi-official module list - ability of module author to polish it in his own tempo using more extensive field test results. I actually kind of think "etc." should be deprecated and eventually removed from Phobos at all. For C bindings we now have Deimos, for experimental packages it simply does not work that good.On 10/6/13 10:10 AM, David Nadlinger wrote:I'm largely staying out of this conversation, but there's one area that I think is pretty important, speed of development. By having a less official, more readily committable to, repository it stands to reason that it'll evolve faster and fluidly than the phobos code base docs or should. Some of it is just that phobos pull requests lanquish too long, but that's not ALL it is. The bar should be different, not that phobos' bar should be lower. My 2 cents, BradOn Sunday, 6 October 2013 at 17:08:25 UTC, Joseph Rushton Wakeling wrote:We could improve things on our end by featuring etc documentation more prominently etc. I don't think there's a need to reboot things with stdx. Just improve etc. Andreiisn't this really what has just been discussed under the proposed name of stdx? ... and if so, why isn't it being used?This is exactly why I'm not too thrilled to make another attempt at establishing something like that. ;)
Oct 07 2013
On 10/6/13 9:57 AM, David Nadlinger wrote:On Saturday, 5 October 2013 at 00:24:22 UTC, Andrei Alexandrescu wrote:I think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost). Andrei2. I do vote for inclusion in the /etc/ package for the time being.What is your vision for the future of etc.*, assuming that we are also going to promote DUB (or another package manager) to "official" status soon as well?
Oct 06 2013
On 2013-10-06 22:40, Andrei Alexandrescu wrote:I think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed. -- /Jacob Carlborg
Oct 06 2013
On Monday, October 07, 2013 08:36:16 Jacob Carlborg wrote:On 2013-10-06 22:40, Andrei Alexandrescu wrote:That's what I thought that it was for. I don't remember etc ever really being discussed before, and all it has are C bindings, so the idea that it would hold anything other than C bindings is news to me, though I think that we should probably shy away from putting C bindings in Phobos in general. - Jonathan M DaviI think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed.
Oct 07 2013
On Monday, 7 October 2013 at 07:12:13 UTC, Jonathan M Davis wrote:On Monday, October 07, 2013 08:36:16 Jacob Carlborg wrote:The problem is, if these C bindings are removed, the immediate reflex will be to think that Phobos doesn't have the features that were fulfilled by these bindings. So the impulse will be to reinvent the wheel, when these bindings are perfectly okay and do the job well. C bindings is a way to save us time and build upon proven quality libraries. I don't see any problem with C bindings being in the standard library, as long as they are really useful and high quality. The "not invented here" itch is a bad one. The workforce of the community should be directed at real problems and filling real gaps, rather than being wasted at reinventing the wheel merely for aethetic/ideological reasons. I don't see any need to remove etc.On 2013-10-06 22:40, Andrei Alexandrescu wrote:That's what I thought that it was for. I don't remember etc ever really being discussed before, and all it has are C bindings, so the idea that it would hold anything other than C bindings is news to me, though I think that we should probably shy away from putting C bindings in Phobos in general. - Jonathan M DaviI think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed.
Oct 12 2013
On Saturday, October 12, 2013 11:09:21 SomeDude wrote:On Monday, 7 October 2013 at 07:12:13 UTC, Jonathan M Davis wrote:Deimos is for C bindings, not Phobos. We don't want any more modules in std built on top of C bindings for libraries that aren't guaranteed to be on all of the systems that we support. Having std.net.curl has been very problematic due to the problems with getting a proper version of libcurl to link against in Windows, and there has even been some discussion of removing it entirely. So, there will be no more Phobos modules built on anything like curl or openssl or gcrypt or any other C library which isn't guaranteed to be on all systems. That being the case, there's no point in putting C bindings in Phobos. Deimos was created specifically so that there wolud be a place to get bindings to C libraries. We may want to make some adjustments to how Deimos is handled, but it's our solution to C bindings, not Phobos: https://github.com/D-Programming-Deimos druntime should have C bindings for the OSes that we support, but that's the only C bindings that should be in D's standard libraries. Whether we'll remove any that we have is still up for debate, but we're not adding any more. - Jonathan M DavisOn Monday, October 07, 2013 08:36:16 Jacob Carlborg wrote:The problem is, if these C bindings are removed, the immediate reflex will be to think that Phobos doesn't have the features that were fulfilled by these bindings. So the impulse will be to reinvent the wheel, when these bindings are perfectly okay and do the job well. C bindings is a way to save us time and build upon proven quality libraries. I don't see any problem with C bindings being in the standard library, as long as they are really useful and high quality. The "not invented here" itch is a bad one. The workforce of the community should be directed at real problems and filling real gaps, rather than being wasted at reinventing the wheel merely for aethetic/ideological reasons. I don't see any need to remove etc.On 2013-10-06 22:40, Andrei Alexandrescu wrote:That's what I thought that it was for. I don't remember etc ever really being discussed before, and all it has are C bindings, so the idea that it would hold anything other than C bindings is news to me, though I think that we should probably shy away from putting C bindings in Phobos in general. - Jonathan M DaviI think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed.
Oct 12 2013
Am 13.10.2013 01:11, schrieb Jonathan M Davis:On Saturday, October 12, 2013 11:09:21 SomeDude wrote:+1 for removing std.net.curl. -- PauloOn Monday, 7 October 2013 at 07:12:13 UTC, Jonathan M Davis wrote:Deimos is for C bindings, not Phobos. We don't want any more modules in std built on top of C bindings for libraries that aren't guaranteed to be on all of the systems that we support. Having std.net.curl has been very problematic due to the problems with getting a proper version of libcurl to link against in Windows, and there has even been some discussion of removing it entirely. So, there will be no more Phobos modules built on anything like curl or openssl or gcrypt or any other C library which isn't guaranteed to be on all systems. That being the case, there's no point in putting C bindings in Phobos. Deimos was created specifically so that there wolud be a place to get bindings to C libraries. We may want to make some adjustments to how Deimos is handled, but it's our solution to C bindings, not Phobos: https://github.com/D-Programming-Deimos druntime should have C bindings for the OSes that we support, but that's the only C bindings that should be in D's standard libraries. Whether we'll remove any that we have is still up for debate, but we're not adding any more. - Jonathan M DavisOn Monday, October 07, 2013 08:36:16 Jacob Carlborg wrote:The problem is, if these C bindings are removed, the immediate reflex will be to think that Phobos doesn't have the features that were fulfilled by these bindings. So the impulse will be to reinvent the wheel, when these bindings are perfectly okay and do the job well. C bindings is a way to save us time and build upon proven quality libraries. I don't see any problem with C bindings being in the standard library, as long as they are really useful and high quality. The "not invented here" itch is a bad one. The workforce of the community should be directed at real problems and filling real gaps, rather than being wasted at reinventing the wheel merely for aethetic/ideological reasons. I don't see any need to remove etc.On 2013-10-06 22:40, Andrei Alexandrescu wrote:That's what I thought that it was for. I don't remember etc ever really being discussed before, and all it has are C bindings, so the idea that it would hold anything other than C bindings is news to me, though I think that we should probably shy away from putting C bindings in Phobos in general. - Jonathan M DaviI think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed.
Oct 13 2013
On Saturday, 12 October 2013 at 23:12:03 UTC, Jonathan M Davis wrote:- Jonathan M DavisOK, for libraries that are not well supported on all platforms, that makes sense.
Oct 13 2013
On Sunday, October 13, 2013 19:09:36 SomeDude wrote:On Saturday, 12 October 2013 at 23:12:03 UTC, Jonathan M Davis wrote:Yeah, and because Windows supports basically nothing out of the box except its own OS libraries (e.g. Win32 or WinRT), that means not supporting anything other than C bindings to the OS functions and leaving all other C bindings to something outside of the standard library like Deimos. But if we promote deimos properly (and dub will probably help with this), we should be able to make people aware of where they can find bindings to C libraries and make it less likely that people will reinvent the wheel in D if it's not actually worth doing (though in some cases it is worth doing - e.g. thanks to slicing, well-written D parsing libraries are likely to beat any C/C++ parsing libraries that operate on null-terminated strings). - Jonathan M Davis- Jonathan M DavisOK, for libraries that are not well supported on all platforms, that makes sense.
Oct 13 2013
On 13/10/13 01:11, Jonathan M Davis wrote:On Saturday, October 12, 2013 11:09:21 SomeDude wrote:+1 for removing std.net.curl too -- Jordi SayolOn Monday, 7 October 2013 at 07:12:13 UTC, Jonathan M Davis wrote:Deimos is for C bindings, not Phobos. We don't want any more modules in std built on top of C bindings for libraries that aren't guaranteed to be on all of the systems that we support. Having std.net.curl has been very problematic due to the problems with getting a proper version of libcurl to link against in Windows, and there has even been some discussion of removing it entirely. So, there will be no more Phobos modules built on anything like curl or openssl or gcrypt or any other C library which isn't guaranteed to be on all systems. That being the case, there's no point in putting C bindings in Phobos. Deimos was created specifically so that there wolud be a place to get bindings to C libraries. We may want to make some adjustments to how Deimos is handled, but it's our solution to C bindings, not Phobos: https://github.com/D-Programming-Deimos druntime should have C bindings for the OSes that we support, but that's the only C bindings that should be in D's standard libraries. Whether we'll remove any that we have is still up for debate, but we're not adding any more. - Jonathan M DavisOn Monday, October 07, 2013 08:36:16 Jacob Carlborg wrote:The problem is, if these C bindings are removed, the immediate reflex will be to think that Phobos doesn't have the features that were fulfilled by these bindings. So the impulse will be to reinvent the wheel, when these bindings are perfectly okay and do the job well. C bindings is a way to save us time and build upon proven quality libraries. I don't see any problem with C bindings being in the standard library, as long as they are really useful and high quality. The "not invented here" itch is a bad one. The workforce of the community should be directed at real problems and filling real gaps, rather than being wasted at reinventing the wheel merely for aethetic/ideological reasons. I don't see any need to remove etc.On 2013-10-06 22:40, Andrei Alexandrescu wrote:That's what I thought that it was for. I don't remember etc ever really being discussed before, and all it has are C bindings, so the idea that it would hold anything other than C bindings is news to me, though I think that we should probably shy away from putting C bindings in Phobos in general. - Jonathan M DaviI think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost).Currently "etc" seems like where C bindings are placed.
Oct 13 2013
On Sunday, 6 October 2013 at 20:40:50 UTC, Andrei Alexandrescu wrote:On 10/6/13 9:57 AM, David Nadlinger wrote:Please consider the stdx proposal instead. etc was always used for C bindings...On Saturday, 5 October 2013 at 00:24:22 UTC, Andrei Alexandrescu wrote:I think /etc/ should be a stepping stone to std, just like in C++ boost is for std (and boost's sandbox is for boost). Andrei2. I do vote for inclusion in the /etc/ package for the time being.What is your vision for the future of etc.*, assuming that we are also going to promote DUB (or another package manager) to "official" status soon as well?
Oct 07 2013
On 10/4/13 5:24 PM, Andrei Alexandrescu wrote:On 10/2/13 7:41 AM, Dicebot wrote:[snip] To put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46d It contains some rather unsavory bits (I'm sure a ctRegex would be nicer for parsing numbers etc), but it works on a lot of code just swell. Most importantly, there's a clear distinction between the generic core and the C++-specific part. It should be obvious how to use the generic matcher for defining a D tokenizer. Token representation is minimalistic and expressive. Just write tk!"<<" for left shift, tk!"int" for int etc. Typos will be detected during compilation. One does NOT need to define and use TK_LEFTSHIFT or TK_INT; all needed by the generic tokenizer is the list of tokens. In return, it offers an efficient trie-based matcher for all tokens. (Keyword matching is unusual in that keywords are first found by the trie matcher, and then a simple check figures whether more characters follow, e.g. "if" vs. "iffy". Given that many tokenizers use a hashtable anyway to look up all symbols, there's no net loss of speed with this approach.) The lexer generator compiles fast and should run fast. If not, it should be easy to improve at the matcher level. Now, what I'm asking for is that std.d.lexer builds on this design instead of the traditional one. At a slight delay, we get the proverbial fishing rod IN ADDITION TO of the equally proverbial fish, FOR FREE. It is quite evident there's a bunch of code sharing going on already between std.d.lexer and the proposed design, so it shouldn't be hard to effect the adaptation. So with this I'm leaving it all within the hands of the submitter and the review manager. I didn't count the votes, but we may have a "yes" majority built up. Since additional evidence has been introduce, I suggest at least a revote. Ideally, there would be enough motivation for Brian to suspend the review and integrate the proposed design within std.d.lexer. AndreiAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. But there's plenty of good news. 1. I am not attempting to veto this, so just consider it a normal vote when tallying. 2. I do vote for inclusion in the /etc/ package for the time being. 3. The work is good and the code valuable, so even in the case my suggestions (below) will be followed, a virtually all code pulp that gets work done can be reused.
Oct 07 2013
On Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:http://dpaste.dzfl.pl/d07dd46dI have to say, that `generateCases` function is rather disgusting. I'm really worried about the trend of using string mixins when not necessary, for no apparent gain. Surely you could have used static foreach to generate those cases instead, allowing code that is actually readable. It would probably have much better compile-time performance as well, but that's just speculation.
Oct 07 2013
On 10/7/13 9:21 PM, Jakob Ovrum wrote:On Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:This is the first shot, and I'm more interested in the API with the implementation to be improved. Your idea sounds great - care to put it in code so we see how it does? Andreihttp://dpaste.dzfl.pl/d07dd46dI have to say, that `generateCases` function is rather disgusting. I'm really worried about the trend of using string mixins when not necessary, for no apparent gain. Surely you could have used static foreach to generate those cases instead, allowing code that is actually readable. It would probably have much better compile-time performance as well, but that's just speculation.
Oct 07 2013
On 10/7/13 9:26 PM, Andrei Alexandrescu wrote:On 10/7/13 9:21 PM, Jakob Ovrum wrote:FWIW I just tried this, and it seems to work swell. int main(string[] args) { alias TypeTuple!(1, 2, 3, 4) tt; int a; switch (args.length) { foreach (i, _; tt) { case i + 1: return i * 42; } default: break; } return 0; } Interesting! AndreiOn Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:This is the first shot, and I'm more interested in the API with the implementation to be improved. Your idea sounds great - care to put it in code so we see how it does? Andreihttp://dpaste.dzfl.pl/d07dd46dI have to say, that `generateCases` function is rather disgusting. I'm really worried about the trend of using string mixins when not necessary, for no apparent gain. Surely you could have used static foreach to generate those cases instead, allowing code that is actually readable. It would probably have much better compile-time performance as well, but that's just speculation.
Oct 07 2013
On 10/7/13 9:34 PM, Andrei Alexandrescu wrote:On 10/7/13 9:26 PM, Andrei Alexandrescu wrote:On the other hand, I find it difficult to figure how the needed processing can be done with reasonable ease with just the above. So I guess it's your turn. AndreiOn 10/7/13 9:21 PM, Jakob Ovrum wrote:FWIW I just tried this, and it seems to work swell. int main(string[] args) { alias TypeTuple!(1, 2, 3, 4) tt; int a; switch (args.length) { foreach (i, _; tt) { case i + 1: return i * 42; } default: break; } return 0; } Interesting! AndreiOn Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:This is the first shot, and I'm more interested in the API with the implementation to be improved. Your idea sounds great - care to put it in code so we see how it does? Andreihttp://dpaste.dzfl.pl/d07dd46dI have to say, that `generateCases` function is rather disgusting. I'm really worried about the trend of using string mixins when not necessary, for no apparent gain. Surely you could have used static foreach to generate those cases instead, allowing code that is actually readable. It would probably have much better compile-time performance as well, but that's just speculation.
Oct 07 2013
On Tuesday, 8 October 2013 at 04:37:31 UTC, Andrei Alexandrescu wrote:So I guess it's your turn.I was going to cook something up with `groupBy` (taken from the I'm still adamant this is the way to go, but I'm putting away the torch for now.
Oct 08 2013
On 10/8/13 7:02 AM, Jakob Ovrum wrote:On Tuesday, 8 October 2013 at 04:37:31 UTC, Andrei Alexandrescu wrote:Fair enough. (Again, it would be unfair to compare an existing design against a hypothetical one.) I suspect at some point you will need to generate some custom code, which will come as a string that you need to mixin. But no matter. My most significant bit is, we need a trie lexer generator ONLY from the token strings, no TK_XXX user-provided symbols necessary. If all we need is one language (D) this is a non-issue because the library writer provides the token definitions. If we need to support user-provided languages, having the library manage the string -> small integer mapping becomes essential. AndreiSo I guess it's your turn.I was going to cook something up with `groupBy` (taken from the still open!), but the former isn't CTFEable. Blergh. I'm still adamant this is the way to go, but I'm putting away the torch for now.
Oct 08 2013
On 10/08/2013 05:05 PM, Andrei Alexandrescu wrote:But no matter. My most significant bit is, we need a trie lexer generator ONLY from the token strings, no TK_XXX user-provided symbols necessary. If all we need is one language (D) this is a non-issue because the library writer provides the token definitions. If we need to support user-provided languages, having the library manage the string -> small integer mapping becomes essential.It's good to get rid of the symbol names. You should try to map the strings onto an enum so that final switch works. final switch (t.type_) { case t!"<<": break; // ... }
Oct 09 2013
On 10/9/13 6:10 PM, Martin Nowak wrote:On 10/08/2013 05:05 PM, Andrei Alexandrescu wrote:Excellent point! In fact one would need to use t!"<<".id instead of t!"<<". I'll work on that next. AndreiBut no matter. My most significant bit is, we need a trie lexer generator ONLY from the token strings, no TK_XXX user-provided symbols necessary. If all we need is one language (D) this is a non-issue because the library writer provides the token definitions. If we need to support user-provided languages, having the library manage the string -> small integer mapping becomes essential.It's good to get rid of the symbol names. You should try to map the strings onto an enum so that final switch works. final switch (t.type_) { case t!"<<": break; // ... }
Oct 10 2013
On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:Excellent point! In fact one would need to use t!"<<".id instead of t!"<<". I'll work on that next. AndreiI don't suppose this new lexer is on Github or something. I'd like to help get this new implementation up and running.
Oct 10 2013
On 10/10/13 2:41 PM, Brian Schott wrote:On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:Thanks for your gracious comeback. I was fearing a "My work is not appreciated, I'm not trying to contribute anymore" etc. The code is part of Facebook's project that I mentioned in the announce forum. I am attempting to open source it, should have an answer soon. AndreiExcellent point! In fact one would need to use t!"<<".id instead of t!"<<". I'll work on that next. AndreiI don't suppose this new lexer is on Github or something. I'd like to help get this new implementation up and running.
Oct 10 2013
11-Oct-2013 01:41, Brian Schott пишет:On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:Love this attitude! :) Having helped with std.d.lexer before (w.r.t. to performance mostly) I'm inclined to land a hand in perfecting the more generic one. -- Dmitry OlshanskyExcellent point! In fact one would need to use t!"<<".id instead of t!"<<". I'll work on that next. AndreiI don't suppose this new lexer is on Github or something. I'd like to help get this new implementation up and running.
Oct 11 2013
11-Oct-2013 13:52, Dmitry Olshansky пишет:11-Oct-2013 01:41, Brian Schott пишет:s/land/lend/ -- Dmitry OlshanskyOn Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:Love this attitude! :) Having helped with std.d.lexer before (w.r.t. to performance mostly) I'm inclined to land a hand in perfecting the more generic one.Excellent point! In fact one would need to use t!"<<".id instead of t!"<<". I'll work on that next. AndreiI don't suppose this new lexer is on Github or something. I'd like to help get this new implementation up and running.
Oct 11 2013
On 10/10/2013 07:34 PM, Andrei Alexandrescu wrote:Excellent point! In fact one would need to use t!"<<".id instead of t!"<<"Either adding an alias this from TokenType to the enum or returning the enum in tk!"<<" would circumvent this. See http://dpaste.dzfl.pl/cdcba00d
Oct 10 2013
On Monday, October 07, 2013 17:16:45 Andrei Alexandrescu wrote:So with this I'm leaving it all within the hands of the submitter and the review manager. I didn't count the votes, but we may have a "yes" majority built up. Since additional evidence has been introduce, I suggest at least a revote. Ideally, there would be enough motivation for Brian to suspend the review and integrate the proposed design within std.d.lexer.I think that it's worth noting that if this vote passes, it will be the first vote for a Phobos module which passed and had any "no" votes cast against it (at least, if any of the previous modules had any "no" votes, I don't recall them; it's always been overwhelmingly in favor of inclusion). That in and of itself implies that the situation needs further examination. Though maybe it's simply that this particular module is in an area where we have more posters with strong opinions. Also, in general, I tend to think that we should move towards not merging new modules into Phobos as quickly as we have in the past. Whether the "stdx" proposal is the way to go or not is another matter, but I think that we should aim for having modules be more battle-tested before actually becoming full- fledged modules in Phobos. We've had great stuff reviewed and merged thus far, but we also tend to end up having to make minor tweaks to the API or later come to regret including it at all (e.g. std.net.curl). Having some sort of intermediate step prior to full inclusion for at least one or two releases would be a good move IMHO. - Jonathan M Davis
Oct 07 2013
On Tuesday, 8 October 2013 at 05:22:32 UTC, Jonathan M Davis wrote:I think that it's worth noting that if this vote passes, it will be the first vote for a Phobos module which passed and had any "no" votes cast against it (at least, if any of the previous modules had any "no" votes, I don't recall them; it's always been overwhelmingly in favor of inclusion). That in and of itself implies that the situation needs further examination. Though maybe it's simply that this particular module is in an area where we have more posters with strong opinions.I had noticed this. I'm not sure if a simple majority is good enough for the standard library.
Oct 07 2013
On Tuesday, 8 October 2013 at 05:22:32 UTC, Jonathan M Davis wrote:I think that it's worth noting that if this vote passes, it will be the first vote for a Phobos module which passed and had any "no" votes cast against it (at least, if any of the previous modules had any "no" votes, I don't recall them; it's always been overwhelmingly in favor of inclusion).Guess what was the main point of my concerns while following this voting thread. Until now there were at most one "No" vote for accepted proposals and exact "Yes" vote threshold is defined anywhere. When voting will end I will sum up some format stats on topic and after some hard thinking will make separate announcement/topic possible outcomes.
Oct 08 2013
On 10/08/2013 07:22 AM, Jonathan M Davis wrote:We've had great stuff reviewed and merged thus far, but we also tend to end up having to make minor tweaks to the API or later come to regret including it at all (e.g. std.net.curl). Having some sort of intermediate step prior to full inclusion for at least one or two releases would be a good move IMHO.It usually takes me a few month until I get to try a new module at which point it's mostly already voted and included. So the current approach doesn't work for me at all.
Oct 09 2013
On Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:To put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46dWhy do you use "\0" as end-of-stream token: /** * All token types include regular and reservedTokens, plus the null * token ("") and the end-of-stream token ("\0"). */ We can have situation when the "\0" is a valid token, for example for binary formats. Is it possible to indicate end-of-stream another way, maybe via "empty" property for range-based API?
Oct 08 2013
On 10/8/13 11:11 PM, ilya-stromberg wrote:On Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:I'm glad you asked. It's simply a decision by convention. I know no C++ source can contain a "\0", so I append it to the input and use it as a sentinel. A general lexer should take the EOF symbol as a parameter. One more thing: the trie matcher knows a priori (statically) what the maximum lookahead is - it's the maximum of all symbols. That can be used to pre-fill the input buffer such that there's never an out-of-bounds access, even with input ranges. AndreiTo put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46dWhy do you use "\0" as end-of-stream token: /** * All token types include regular and reservedTokens, plus the null * token ("") and the end-of-stream token ("\0"). */ We can have situation when the "\0" is a valid token, for example for binary formats. Is it possible to indicate end-of-stream another way, maybe via "empty" property for range-based API?
Oct 09 2013
On Wednesday, 9 October 2013 at 07:49:55 UTC, Andrei Alexandrescu wrote:On 10/8/13 11:11 PM, ilya-stromberg wrote:So, it's interesting to see a new improved API, because we need a really generic lexer. I think it's not so difficult.On Tuesday, 8 October 2013 at 00:16:45 UTC, Andrei Alexandrescu wrote:I'm glad you asked. It's simply a decision by convention. I know no C++ source can contain a "\0", so I append it to the input and use it as a sentinel. A general lexer should take the EOF symbol as a parameter. One more thing: the trie matcher knows a priori (statically) what the maximum lookahead is - it's the maximum of all symbols. That can be used to pre-fill the input buffer such that there's never an out-of-bounds access, even with input ranges. AndreiTo put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46dWhy do you use "\0" as end-of-stream token: /** * All token types include regular and reservedTokens, plus the null * token ("") and the end-of-stream token ("\0"). */ We can have situation when the "\0" is a valid token, for example for binary formats. Is it possible to indicate end-of-stream another way, maybe via "empty" property for range-based API?
Oct 09 2013
On 10/7/13 5:16 PM, Andrei Alexandrescu wrote:On 10/4/13 5:24 PM, Andrei Alexandrescu wrote:I made an improvement to the way tokens are handled. In the paste above, "tk" is a function. A CTFE-able function that just returns a compile-time constant, but a function nevertheless. To actually reduce "tk" to a compile-time constant in all cases, I changed it as follows: template tk(string symbol) { import std.range; static if (symbol == "") { // Token ID 0 is reserved for "unrecognized token". enum tk = TokenType2(0); } else static if (symbol == "\0") { // Token ID max is reserved for "end of input". enum tk = TokenType2( cast(TokenIDRep) (1 + tokens.length + reservedTokens.length)); } else { //enum id = chain(tokens, reservedTokens).countUntil(symbol); // Find the id within the regular tokens realm enum idTokens = tokens.countUntil(symbol); static if (idTokens >= 0) { // Found, regular token. Add 1 because 0 is reserved. enum id = idTokens + 1; } else { // not found, only chance is within the reserved tokens realm enum idResTokens = reservedTokens.countUntil(symbol); enum id = idResTokens >= 0 ? tokens.length + idResTokens + 1 : -1; } static assert(id >= 0 && id < TokenIDRep.max, "Invalid token: " ~ symbol); enum tk = TokenType2(id); } This is even better now because token types are simple static constants. AndreiOn 10/2/13 7:41 AM, Dicebot wrote:[snip] To put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46dAfter brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. But there's plenty of good news. 1. I am not attempting to veto this, so just consider it a normal vote when tallying. 2. I do vote for inclusion in the /etc/ package for the time being. 3. The work is good and the code valuable, so even in the case my suggestions (below) will be followed, a virtually all code pulp that gets work done can be reused.
Oct 09 2013
08-Oct-2013 04:16, Andrei Alexandrescu пишет:On 10/4/13 5:24 PM, Andrei Alexandrescu wrote: To put my money where my mouth is, I have a proof-of-concept tokenizer for C++ in working state. http://dpaste.dzfl.pl/d07dd46d It contains some rather unsavory bits (I'm sure a ctRegex would be nicer for parsing numbers etc), but it works on a lot of code just swell.No - ctRegex as it stands right now is too generic and conservative with the code it generates so "\d+" would do: a) use full Unicode for "Number" b) keep tabs on where to return as if there could be ambiguity of how many '\d' it may eat (no maximal munch etc.). The reason is that the fact that said '\d+' may be in the middle of some pattern (e.g. 9\d+0), and the fact that it's unambiguous on its own is not exploited. Both are quite suboptimal and there is a long road I going to take to have a _general_ solution for both points. One day we would reach that goal though. ATM just hack your way through if pattern is sooo simple.Most importantly, there's a clear distinction between the generic core and the C++-specific part. It should be obvious how to use the generic matcher for defining a D tokenizer.Token representation is minimalistic and expressive. Just write tk!"<<" for left shift, tk!"int" for int etc. Typos will be detected during compilation. One does NOT need to define and use TK_LEFTSHIFT or TK_INT; all needed by the generic tokenizer is the list of tokens. In return, it offers an efficient trie-based matcher for all tokens. (Keyword matching is unusual in that keywords are first found by the trie matcher, and then a simple check figures whether more characters follow, e.g. "if" vs. "iffy".+1 Given that many tokenizers use a hashtableanyway to look up all symbols, there's no net loss of speed with this approach.Yup. The only benefit is slimmer giant switch. Another "hybrid" option is insated of hash-table use a generated keyword trie searcher separately as a function. Then just test each identifier with it. This is what std.d.lexer does and is quite fast. (awaiting latest benchmarks)The lexer generator compiles fast and should run fast. If not, it should be easy to improve at the matcher level. Now, what I'm asking for is that std.d.lexer builds on this design instead of the traditional one. At a slight delay, we get the proverbial fishing rod IN ADDITION TO of the equally proverbial fish, FOR FREE. It is quite evident there's a bunch of code sharing going on already between std.d.lexer and the proposed design, so it shouldn't be hard to effect the adaptation.Agreed. Let us take a moment to incorporate a better design.So with this I'm leaving it all within the hands of the submitter and the review manager. I didn't count the votes, but we may have a "yes" majority built up. Since additional evidence has been introduce, I suggest at least a revote. Ideally, there would be enough motivation for Brian to suspend the review and integrate the proposed design within std.d.lexer. Andrei-- Dmitry Olshansky
Oct 11 2013
On 10/4/2013 5:24 PM, Andrei Alexandrescu wrote:[...]Some points: 1. This is a replacement for the switch statement starting at around line 505 in advance() https://github.com/Hackerpilot/phobos/blob/9bdb7f97bb8021f3b0d0291896b8fe21a6fead23/std/d/lexer.d It is not a replacement for the rest of the lexer. 2. Instead of explicit token type enums, such as: mod, /// % it would just be referred to as: tok!"%" Andrei pointed out to me that he has fixed the latter so it resolves to a small integer - meaning it works efficiently as cases in switch statements. This removes my primary objection to it. 3. This level of abstraction combined with efficient generation cannot be currently done in any other language. Hence, it makes for a sweet showcase of what D can do. Hence, I think we ought to adapt Brian's lexer by replacing the switch with Andrei's trie searcher, and replacing the enum TokenType with the tok!"string" syntax.
Oct 08 2013
On Wednesday, 9 October 2013 at 01:27:22 UTC, Walter Bright wrote:On 10/4/2013 5:24 PM, Andrei Alexandrescu wrote:Github tip: You can link to a specific line by clicking the line number and copying and pasting your new URL.[...]Some points: 1. This is a replacement for the switch statement starting at around line 505 in advance() https://github.com/Hackerpilot/phobos/blob/9bdb7f97bb8021f3b0d0291896b8fe21a6fead23/std/d/lexer.d
Oct 08 2013
On 10/8/13 6:26 PM, Walter Bright wrote:On 10/4/2013 5:24 PM, Andrei Alexandrescu wrote:Thanks, that's exactly what I had in mind. Also the trie searcher should be exposed by the library so people can implement other languages. Let me make another, more strategic, point. Projects like Rust and Go have dozens of people getting paid to work on them. In the time it takes us to crank one conventional lexer/parser for a language, they can crank five. The answer is we can't win with a conventional approach. We must leverage D's strengths to amplify our speed of execution, and in this context an integrated generic lexer generator is the ticket. There is one thing I neglected to mention, and I apologize for that. Coming with this all on the eve of voting must be quite demotivating for Brian, who's been through all the arduous steps to get his work to production quality. I hope the compensating factor is that the proposed change is a net positive for the greater good. Andrei[...]Some points: 1. This is a replacement for the switch statement starting at around line 505 in advance() https://github.com/Hackerpilot/phobos/blob/9bdb7f97bb8021f3b0d0291896b8fe21a6fead23/std/d/lexer.d It is not a replacement for the rest of the lexer. 2. Instead of explicit token type enums, such as: mod, /// % it would just be referred to as: tok!"%" Andrei pointed out to me that he has fixed the latter so it resolves to a small integer - meaning it works efficiently as cases in switch statements. This removes my primary objection to it. 3. This level of abstraction combined with efficient generation cannot be currently done in any other language. Hence, it makes for a sweet showcase of what D can do. Hence, I think we ought to adapt Brian's lexer by replacing the switch with Andrei's trie searcher, and replacing the enum TokenType with the tok!"string" syntax.
Oct 08 2013
On Wednesday, 9 October 2013 at 03:55:42 UTC, Andrei Alexandrescu wrote:On 10/8/13 6:26 PM, Walter Bright wrote:Overall, I think this is going into the right direction. However, there is one thing I don't like with that design. When you go throw the big switch of death, you match the beginning of the string and then you go back to a function that will test where does it come from and act accordingly. That is kind of wasteful. What SDC does is that it calls a function-template with the part matched by the big switch of death passed as template argument. The nice thing about it is that it is easy to trnsform this compile time argument into a runtime one by simply forwarding it (what is done to parse identifier that begins by a keyword for instance).On 10/4/2013 5:24 PM, Andrei Alexandrescu wrote:Thanks, that's exactly what I had in mind. Also the trie searcher should be exposed by the library so people can implement other languages. Let me make another, more strategic, point. Projects like Rust and Go have dozens of people getting paid to work on them. In the time it takes us to crank one conventional lexer/parser for a language, they can crank five. The answer is we can't win with a conventional approach. We must leverage D's strengths to amplify our speed of execution, and in this context an integrated generic lexer generator is the ticket. There is one thing I neglected to mention, and I apologize for that. Coming with this all on the eve of voting must be quite demotivating for Brian, who's been through all the arduous steps to get his work to production quality. I hope the compensating factor is that the proposed change is a net positive for the greater good. Andrei[...]Some points: 1. This is a replacement for the switch statement starting at around line 505 in advance() https://github.com/Hackerpilot/phobos/blob/9bdb7f97bb8021f3b0d0291896b8fe21a6fead23/std/d/lexer.d It is not a replacement for the rest of the lexer. 2. Instead of explicit token type enums, such as: mod, /// % it would just be referred to as: tok!"%" Andrei pointed out to me that he has fixed the latter so it resolves to a small integer - meaning it works efficiently as cases in switch statements. This removes my primary objection to it. 3. This level of abstraction combined with efficient generation cannot be currently done in any other language. Hence, it makes for a sweet showcase of what D can do. Hence, I think we ought to adapt Brian's lexer by replacing the switch with Andrei's trie searcher, and replacing the enum TokenType with the tok!"string" syntax.
Oct 08 2013
On 10/8/13 9:32 PM, deadalnix wrote:Overall, I think this is going into the right direction. However, there is one thing I don't like with that design. When you go throw the big switch of death, you match the beginning of the string and then you go back to a function that will test where does it come from and act accordingly. That is kind of wasteful. What SDC does is that it calls a function-template with the part matched by the big switch of death passed as template argument. The nice thing about it is that it is easy to trnsform this compile time argument into a runtime one by simply forwarding it (what is done to parse identifier that begins by a keyword for instance).I think a bit of code would make all that much clearer. Andrei
Oct 08 2013
On Wednesday, 9 October 2013 at 04:38:02 UTC, Andrei Alexandrescu wrote:On 10/8/13 9:32 PM, deadalnix wrote:Sure. So here is the lexer generation infos (this can be simplified by using the tok!"foobar" thing) : http://dpaste.dzfl.pl/7ec225ee Using theses infos, a huge switch based boilerplate is generated. Each "leaf" of the huge switch tree call a function template as follow, by passing as template argument what has been matched so far. You can then proceed as follow : http://dpaste.dzfl.pl/f2f0d22c You may wonder about the "?lexComment". The boilerplate generator understand ? as an indication that lexComment may or may not return a token (depending on lexer configuration) and generate what is needed to handle that (by testing if the function return a token, via some static ifs). You obviously ends up with a log of instance of lexIdentifier(string s)(), but this simply forward to lexIdentifier()(string s) and the forwarding function is removed trivially by the inliner.Overall, I think this is going into the right direction. However, there is one thing I don't like with that design. When you go throw the big switch of death, you match the beginning of the string and then you go back to a function that will test where does it come from and act accordingly. That is kind of wasteful. What SDC does is that it calls a function-template with the part matched by the big switch of death passed as template argument. The nice thing about it is that it is easy to trnsform this compile time argument into a runtime one by simply forwarding it (what is done to parse identifier that begins by a keyword for instance).I think a bit of code would make all that much clearer. Andrei
Oct 08 2013
On Wednesday, 9 October 2013 at 03:55:42 UTC, Andrei Alexandrescu wrote:for the greater good.YOU CALL YOURSELVES A COMMUNITY THAT CARES? http://www.youtube.com/watch?v=yUpbOliTHJY
Oct 08 2013
On 10/8/13 9:33 PM, Brian Schott wrote:On Wednesday, 9 October 2013 at 03:55:42 UTC, Andrei Alexandrescu wrote:I swear I had that in mind when I wrote "the greater good". Awesome movie, and quite fit for the situation :o). Andreifor the greater good.YOU CALL YOURSELVES A COMMUNITY THAT CARES? http://www.youtube.com/watch?v=yUpbOliTHJY
Oct 08 2013
3. This level of abstraction combined with efficient generation cannot be currently done in any other language.This is wrong.
Oct 11 2013
Yes I see the token type discussion as a matter of taste and one that could cleanly be changed using a deprecation path (I wouldn't mind the Tok!str approach, though). I also see no fundamental reason why the API forbids extension for shared sting tables or table-less lexing. And pure implementation details (IMO) shouldn't be a primary voting concern. Much more important is that we don't defer this another year or more for no good reason (changing pure implementation details or purely extending the API are no good reasons when there is a solid implementation/API already). (sorry for the additional rationale)
Oct 06 2013
On 10/06/2013 10:18 AM, Sönke Ludwig wrote:I also see no fundamental reason why the API forbids extension for shared sting tables or table-less lexing.The current API requires to copy slices of the const(ubyte)[] input to string values in every token. This can't be done efficiently without a string table. But a string table is unnecessary for many use-cases, so the API has a built-in performance/memory issue.
Oct 09 2013
Am 10.10.2013 03:25, schrieb Martin Nowak:On 10/06/2013 10:18 AM, Sönke Ludwig wrote:But it could be extended later to accept immutable input as a special case, thus removing that requirement, if I'm not overlooking something. In that case it still is a pure implementation detail.I also see no fundamental reason why the API forbids extension for shared sting tables or table-less lexing.The current API requires to copy slices of the const(ubyte)[] input to string values in every token. This can't be done efficiently without a string table. But a string table is unnecessary for many use-cases, so the API has a built-in performance/memory issue.
Oct 10 2013
On Wednesday, October 02, 2013 16:41:54 Dicebot wrote:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.I'm going to have to vote no. While Brian has done some great work, I think that it's clear from the discussion that there are still some potential issues (e.g. requiring a string table) that need further discussion and possibly API changes. Also, while I question that a generated lexer can beat a hand-written one, I think that we really should look at what Andrei's proposing and look at adjusting whan Brian has done accordingly - or at least do enough so that we can benchmark the two approaches. As such, accepting the lexer right now doesn't really make sense. However, we may want to make it so that the lexer is in some place of prominence (outside of Phobos - probably on dub but mentioned somewhere on dlang.org) as an _experimental_ module which is clearly marked as not finalized but which is ready for people to use and bang on. That way, we may be able to get some better feedback generated from more real world use. - Jonathan M Davis
Oct 09 2013
On Thursday, 10 October 2013 at 04:33:15 UTC, Jonathan M Davis wrote:On Wednesday, October 02, 2013 16:41:54 Dicebot wrote:Vote: No. Same reason as Jonathan above.After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.I'm going to have to vote no. While Brian has done some great work, I think that it's clear from the discussion that there are still some potential issues (e.g. requiring a string table) that need further discussion and possibly API changes. Also, while I question that a generated lexer can beat a hand-written one, I think that we really should look at what Andrei's proposing and look at adjusting whan Brian has done accordingly - or at least do enough so that we can benchmark the two approaches. As such, accepting the lexer right now doesn't really make sense. However, we may want to make it so that the lexer is in some place of prominence (outside of Phobos - probably on dub but mentioned somewhere on dlang.org) as an _experimental_ module which is clearly marked as not finalized but which is ready for people to use and bang on. That way, we may be able to get some better feedback generated from more real world use. - Jonathan M Davis
Oct 10 2013
02-Oct-2013 18:41, Dicebot пишет:After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.I'd have to answer as NO. In order to get to a YES state, it needs: a) Use tok!"==" notation (in line with generic lexer). It makes it far more convenient in the parser down the road as well. b) Ideally use generic lexer framework but it makes for 2 modules to include, so just make it easy to switch to later (no breakage etc.) c) Abstract away string table, let user provide his own hooks for that, and provide a default StringCache. d) Allow operation w/o StringTable at all (make it optional) including "just slice the input" mode. P.S. I'm not a fun of etc.d.lexer. Instead a dub repo seems like a good place for the moment, for these who need it right now. Other may collectively wait for or help in getting to perfection. -- Dmitry Olshansky
Oct 11 2013